Rough Tuning
The process of building a scientific application starts with a general model and ends with a specific piece of software. At each stage in the process, decisions or actions can be taken that can strongly influence the ultimate performance of the software, i.e., the speed at which it produces results.
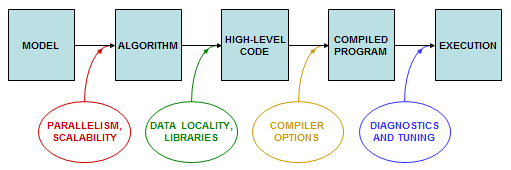
The five boxes in the diagram show five stages of development of a scientific code: model, algorithm, high-level code, compiled code, and execution. Performance can be influenced as the code moves from one stage to the next. Specifically: parallelism and scalability can be designed into the algorithm; data locality can be built into the high-level code, which can also make calls to performance libraries; compiler options can affect the resulting compiled code; and the compiled code can be tuned as it undergoes tests during execution.
The Scalability roadmap focuses on the first step, namely, how to build parallelism into an application. This topic focuses on the middle two steps, which often are intertwined, as we will see. We will not have much to say about the final step, in-depth tuning, as it is a whole subject in itself. Our goal here is simply to introduce the principles and practices that often lead to better performance on a per-core basis, when one is in the midst of code development.
What we will talk about in this topic can be thought of as "rough tuning": applying basic aspects of code optimization that can have a big impact, such as using libraries, or exercising knowledge of compiler flags, along with a few code-writing habits that avoid the worst kinds of performance pitfalls. To do rough tuning, it helps to know about common microarchitectural features like SSE and AVX (to be defined later), and it helps to have a sense of how the compiler tries to optimize instructions to use those features, when given a particular chunk of code.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)