Memory and Variables
We saw earlier that a CUDA kernel can be envisioned as a collection of independent threads divided into blocks, all of which comprise a grid. During concurrent execution on a GPU, the threads in a block get mapped onto CUDA cores within an SM, resulting in parallel speedup. However, this thread-block-grid structure has implications for memory access, too. Next, we discuss the memory locality of variables that are used by threads in CUDA.
Memory Architecture
An NVIDIA GPU has several different memory components available to programmers: registers, shared memory, local memory, global memory, and constant memory. The figure below provides an overview of the memory architecture and illustrates the way its various components are shared (or not) among threads, blocks, and grids in CUDA.
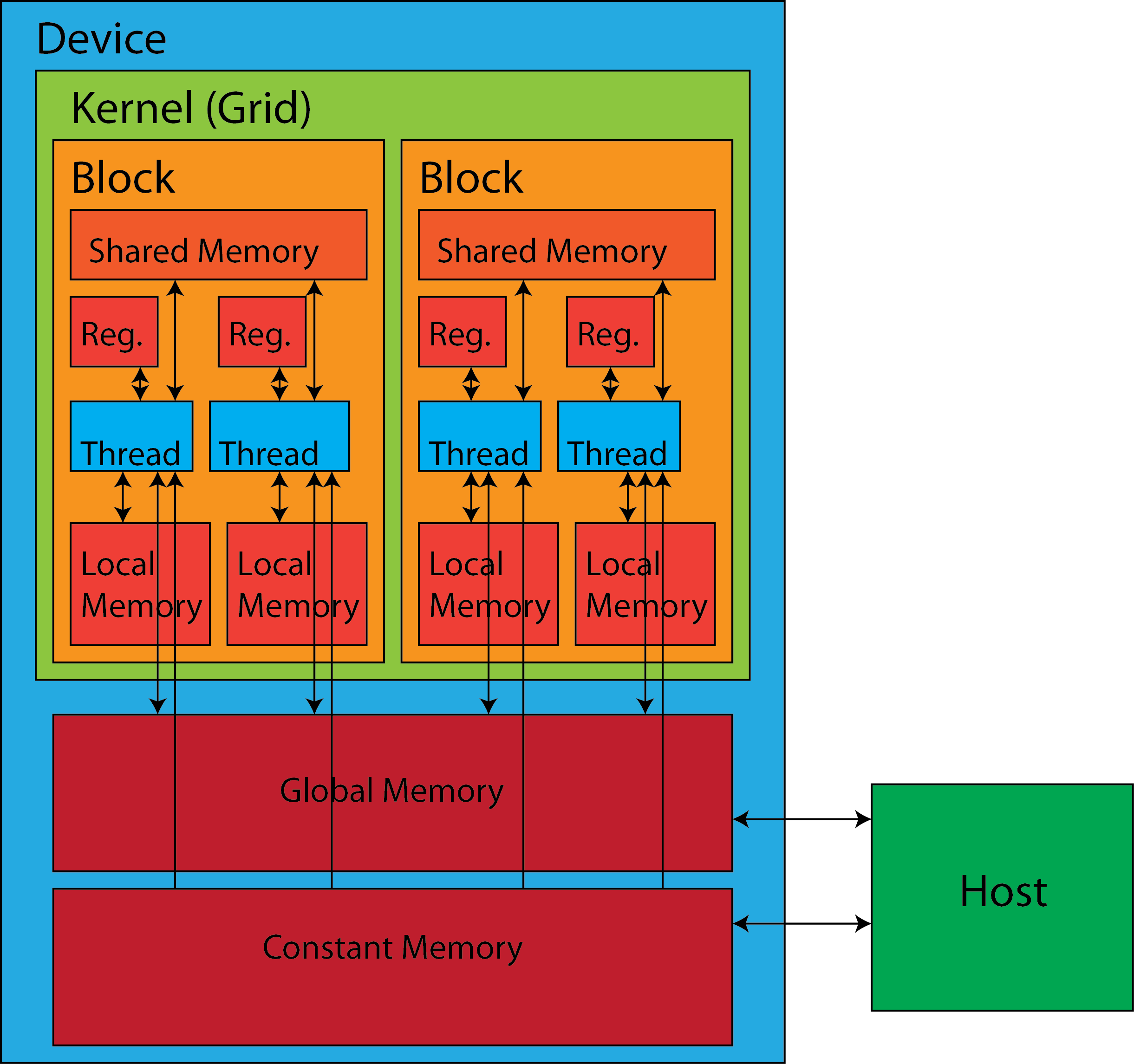
In the figure, the two-way arrows indicate read (R) and write (W) capability. Arrows pointing toward a memory component indicate write capability; arrows pointing away from a memory component indicate read capability. From careful observation, it can be noted that threads have somre form of access to all levels of memory, whereas the host can only access the global memory and the constant memory. Therefore, to load data into the device, the host is involved in copying the data to the global memory or the constant memory. This process is explained more on two subsequent pages, Memory Management and Unified Memory.
Memory Access
Multiple grids can be simultaneously launched on a GPU device. Each grid has its independent workspace and consists of one or more blocks, and each block contains (ideally!) many threads.
From the above diagram, it is evident that threads can communicate with other threads of the same block using shared memory. However, the shared memory for the threads in one block cannot be accessed by threads in a different block. Even within the same block, threads are not able to access the registers and local memory of the other threads. (It should be noted that "local memory" is a conceptual area of memory for storing thread-local variables when register space becomes full; it extends from L1 cache all the way out to global memory.)
The ways in which threads can interact with different parts of memory on the device are summarized below:
| Memory Location | Scope | Access |
|---|---|---|
| Register | per-thread | R/W |
| Local memory | per-thread | R/W |
| Shared memory | per-block | R/W |
| Global memory | per-grid | R/W |
| Constant memory | per-grid | R |
This list is really just a different way of expressing the information contained in the figure. (Technically, global and constant memory can be made visible to multiple grids in separate kernel calls.)
Size and Bandwidth
Different memory components have different sizes and bandwidths. Global memory has the lowest bandwidth but the largest memory size (e.g., 16 GB on the Quadro RTX 5000 GPU found on Frontera). Much like RAM in CPU architecture, global memory can be cached in the on-chip L1 and L2 caches. In contrast, the constant memory size is 64 KB for all compute capabilities; as the name suggests, access from the device is limited to read-only. Constant memory is stored initially in regions of the global memory but is cached in the on-chip constant cache. With specific access patterns, constant memory can be as fast as the registers.
In comparison, shared memory is much faster than global memory and non-cached constant memory, and it is accessible by all threads in the same block. The compute capability of the GPU determines the total shared memory size per streaming multiprocessor (SM), as well as the maximum shared memory per block. For example, the Quadro RTX 5000 GPU has a maximum shared memory size of 64 KB per SM, and the maximum shared memory per block is also 64 KB. The shared memory of an SM is divided among the blocks assigned to the SM.
Each thread can access its own registers and local memory. The registers are on the chip and are the fastest memory component but have the smallest size. The maximum numbers of registers per thread, block, and SM are determined by the compute capability of the GPU. For example, the Quadro RTX 5000 GPU is configured to have 256 registers per thread (1 KB), 65,536 registers per block, and 65,536 registers total per SM (256 KB).
When there are insufficient registers to hold the data, the "spilled" data is stored in local memory. The local memory is much slower than the registers, as it ultimately resides in the global memory, although it may be cached in the L1 and L2 caches. As the name implies, the local memory is private to its thread.
Specifiers and Variable Locations
CUDA supports several memory space specifiers that allow the kernel function to place its variables in distinct memory components. Variables assigned to different memory components also have different lifespans in a CUDA program. The following table (adapted from an online lecture) expands the table above. It shows the possible ways of declaring a variable within a kernel function, and the corresponding location, scope, lifespan, and access (on the device) for the variable. Note especially the role of memory space specifiers such as __shared__.
| Variable Declaration | Location | Scope | Lifespan | Access |
|---|---|---|---|---|
| int Var; // Automatic variable | Register | Thread | Thread | R/W |
| int ArrayVar[N]; // Automatic array | Local | Thread | Thread | R/W |
| __shared__ int SharedVar; | Shared | Block | Block | R/W |
| __device__ int GlobalVar; | Global | Grid | Application | R/W |
| __constant__ int ConstVar; | Constant | Grid | Application | R |
Automatic Variables
An automatic variable is declared without any specifiers. When a device code declares an automatic variable, a copy is generated for all threads of the grid. It resides in the per-thread register and is only accessible by that thread. The automatic variable lasts until the kernel finishes. An automatic variable can be declared in the following manner:
Automatic Arrays
An automatic array variable resides in the per-thread local memory and is only accessible by that thread. Bear in mind that "local memory" really extends out to global memory, so access can be slow. However, it is possible for the compiler to store small automatic arrays in the registers, if all access is done with constant index values. The automatic array lasts until the kernel finishes. An automatic array can be declared in the following manner:
Shared Memory: __shared__
Declaring a variable with the __shared__ memory space specifier explicitly declares that the variable is shared by the threads of a block. The shared memory lasts until the kernel finishes. Including an optional __device__ specifier achieves the same effect.
Global Memory: __device__
When the __device__ specifier is used on variables by itself, it declares the variable to reside in the global memory. The global memory lasts until the program terminates.
Constant Memory: __constant__
Declaring a variable with the __constant__ specifier declares a constant variable that resides in the constant memory. The constant memory lasts until the program terminates. Including an optional __device__ specifier achieves the same effect. The constant variable must be declared outside of any function body.
Assign by Address
The address of a variable declared in the shared, constant, or global memory can be assigned to a pointer variable.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)