OpenMP Offload with Target
OpenMP introduced two more levels of parallelism in version 4.0: simd and target. SIMD allows a single thread to process multiple data elements simultaneously, and target supports offloading a region to devices such as GPUs. Each level of parallelism offers different performance benefits depending on the resources at the program's disposal.
Computing on a GPU or similar device typically requires moving data between two separate memory spaces. The host (the CPU side) has to allocate memory on the device and copy data over before any computation on the device can happen. Once the device finishes, the results need to come back to the host.
With CUDA and other low-level GPU programming models, the programmer is responsible for all of the steps: allocating device memory, copying data in both directions, launching kernels, and cleaning up afterwards. The pseudocode and diagram below give a sense of what that looks like:
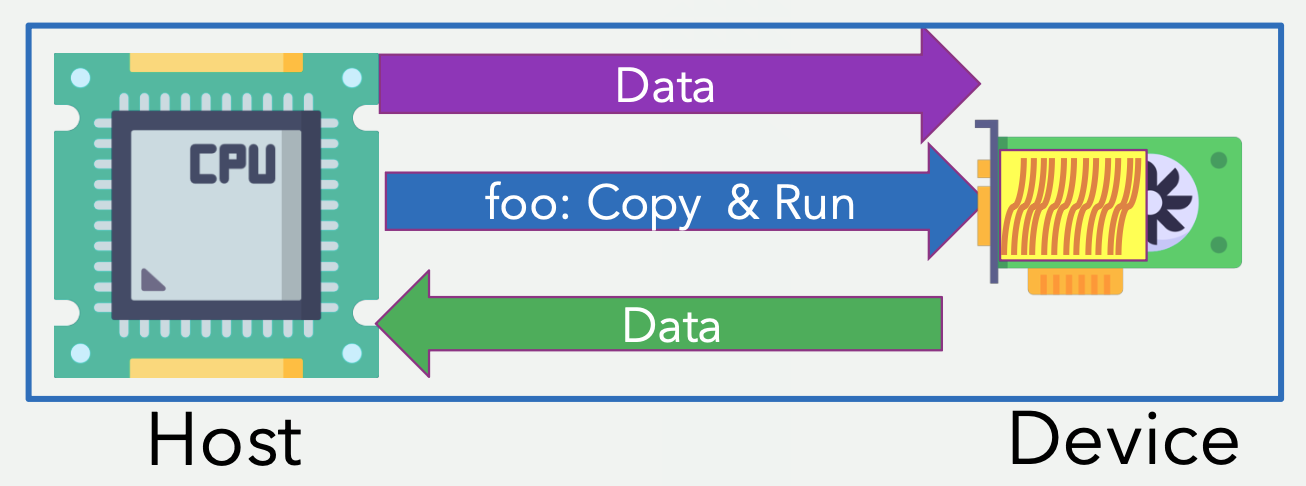
OpenMP can achieve all of that with a single #pragma omp target directive. The code is written as if it were running on the host, and the compiler and runtime take care of the memory management, data transfers, kernel launches, and cleanup. This makes offloading computing to GPUs very easy, as the programmer does not need to learn a whole new GPU programming model.
The variables used in this region are automatically allocated and transferred to the device, and deallocated and transferred back at the end of the structured block. It feels as we have achieved parallel computing on the GPU already, but that is not true. The caveat of the current code above is that the computation is run by a single thread on the GPU, which is vastly less efficient than what we can achieve with full parallelism provided through OpenMP. We will cover how to parallelize the computation and manage memory in detail in the following pages, where we cover the teams and parallel directives.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)