Shared Memory
A shared memory computer has multiple cores with access to the same physical memory. The cores may be part of multicore processor chips, and there may be multiple processors within the computer. If multiple chips are involved, access is not necessarily uniform; from the perspective of an individual core, some physical memory locations have lower latency or higher bandwidth than others. This situation is called non-uniform memory access (NUMA). Nearly all modern computers rely on NUMA designs.
Older chipsets use a single memory controller hub to give every processor equivalent memory access. If access to memory locations is equally fast from all cores, the machine is called a symmetric multiprocessor (SMP). With a shared memory programming model on such a machine and barring contention for the data, tasks running in parallel on all processors can access each other's data equally quickly as accessing their own.

Some chipsets give each processor within a node its own path to a region of memory. Tasks on other processors must send and receive data through neighbors, meaning some shared data is more remote.
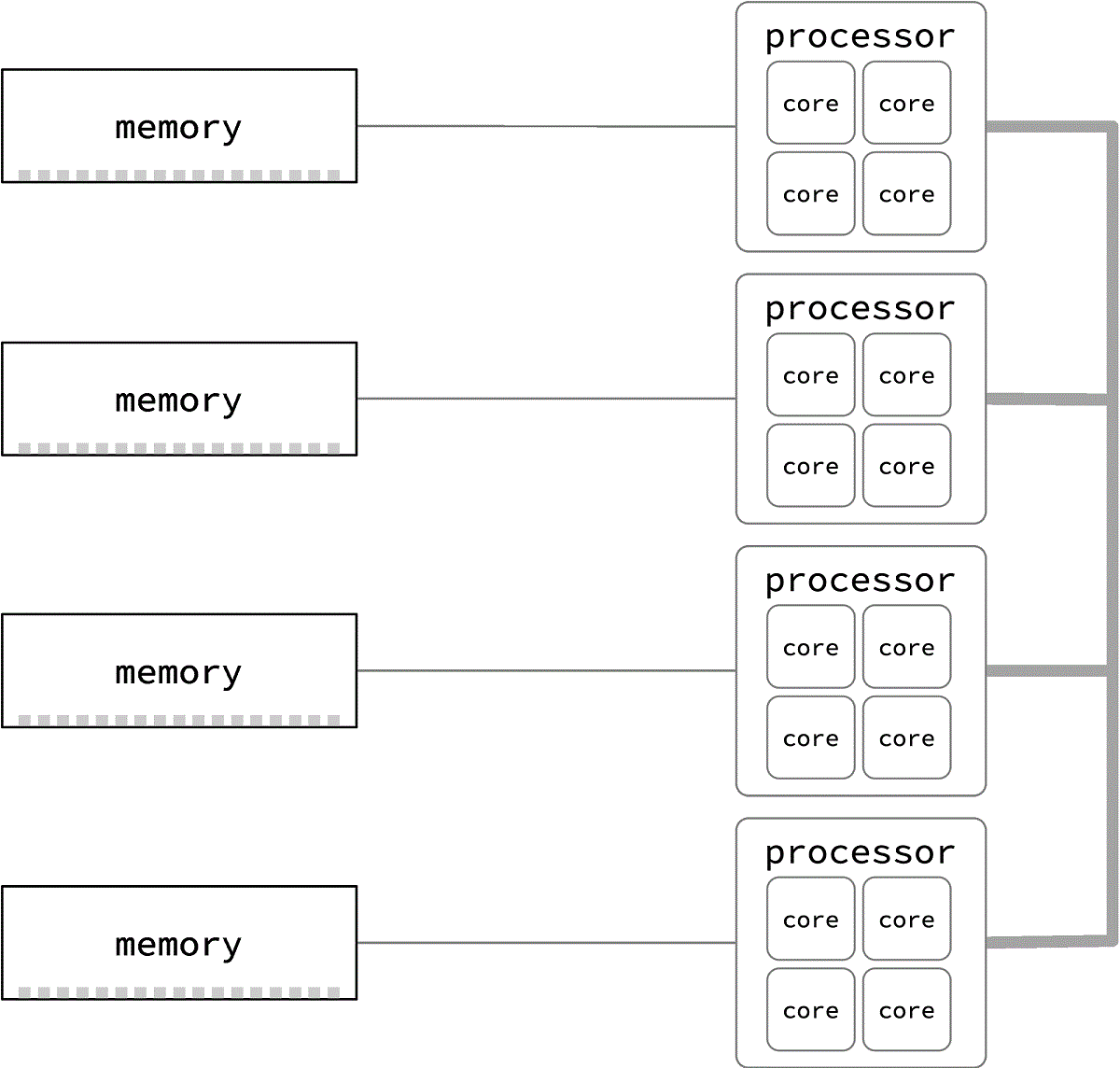
Each memory region above corresponds to a single memory module. Each module is linked to its processor by a single bus. However, a modern processor may have more than one bus, and each bus may have several channels, so that each memory region may consist of a stack of modules.
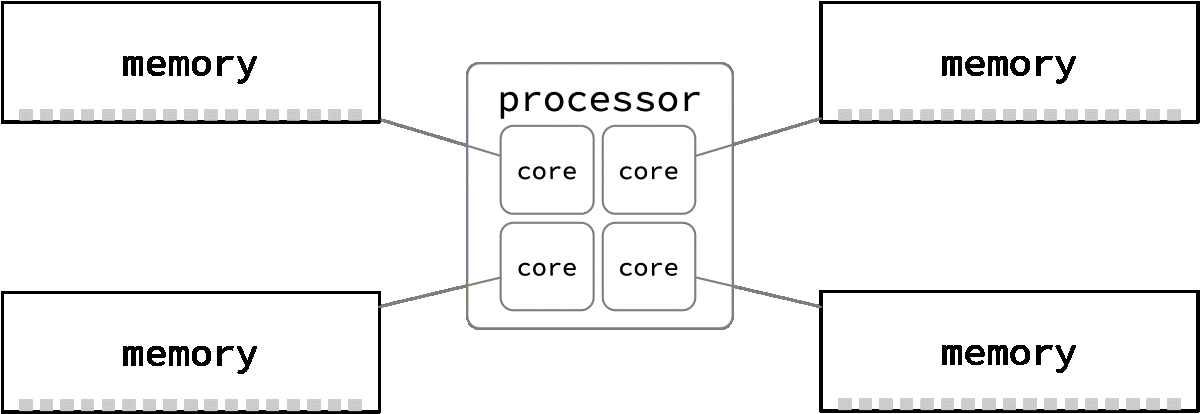
There are even more ways to make a machine classified as NUMA. Here the cores of a single processor each have their own bus to a region of memory. Therefore, each core in this example would be considered a separate "NUMA node," with somewhat faster access to its own associated memory.
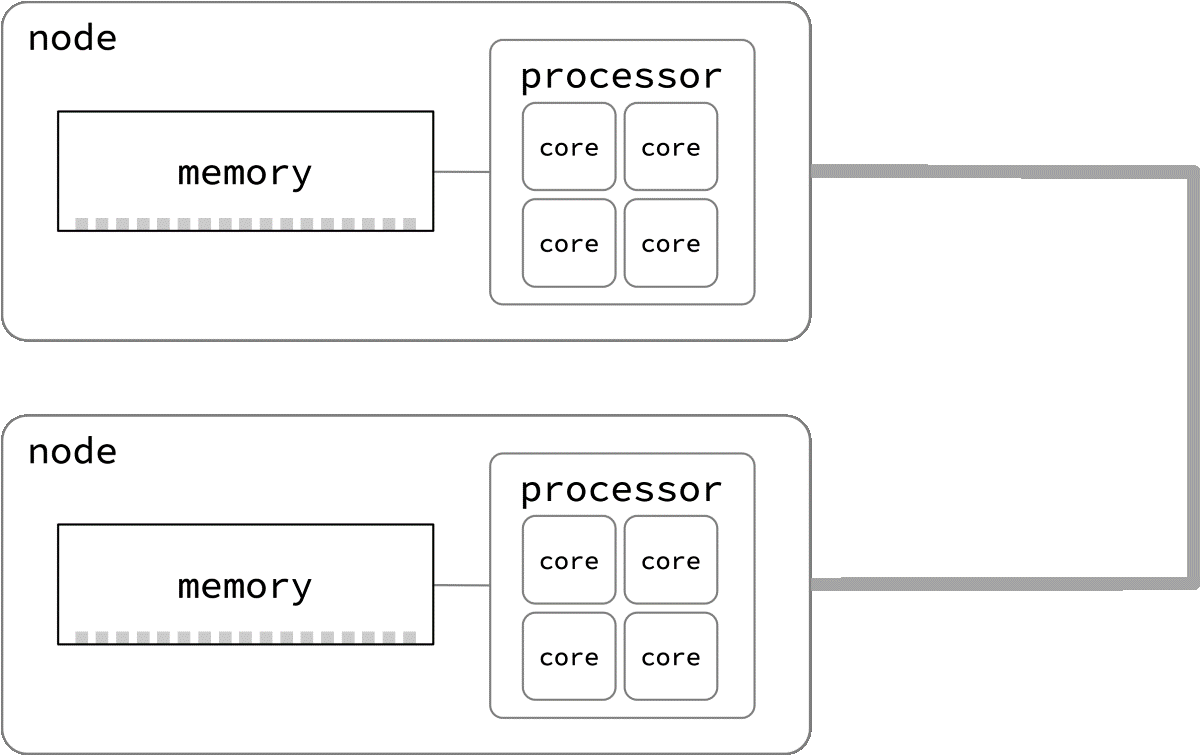
Some architectures use a fast crossbar bus to connect otherwise independent nodes. At a chipset level, these can make the memory on another node look like local memory, but, as with all NUMA machines, there is a greater time cost to reach memory on another node.
Shared memory parallelism is not necessarily the best strategy for supercomputing applications because NUMA is inherent in the design of multi-node systems. Distributed memory or hybrid programming is often better suited for cluster computing. Each supercomputing facility carefully documents their particular architectures to help programmers understand how best to write programs for their specific hardware.
Before designing a shared memory parallel program, take time to understand the architecture of the machines that will run your code. Look for specific recommendations about compiler flags that help leverage the underlying hardware. Using OpenMP directives in otherwise serial programs — and enabling the related compiler flag — counts as shared memory programming because the runtime system sets up a team of threads to parallelize processing.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)