Levels of Communication
There has been an implicit assumption that within our parallel machine, any parallel task can communicate with any other at the same rate. For instance, we've been treating latency and bandwidth as uniform parameters, independent of the sender and receiver. But how good is that assumption on a high-performance cluster like Frontera?
Network characteristics
Once a message leaves a node, are all the other nodes truly reachable at the same speed? Let's look at Frontera's interconnect as an example. Its switch consists of a two-level fat-tree (Clos) network, with a modest 22:18 oversubscription for the branches that lead to the trunk. This means (1) messages are seldom blocked, and and (2) in most cases, senders will see reasonably uniform bandwidth to all destinations. Latency can vary based on the number of "hops" through various switches, but the variation is not huge compared to the slowness of the first jump through the network adapter, which is where the real bottleneck occurs. So for practical purposes, we can treat the inter-node communication cost as homogeneous on Frontera.
Frontera node architecture
A typical Frontera node has two processors which are Intel Cascade Lake 8280s. Inside each processor chip is a 2D mesh interconnect. It joins all 28 cores in that processor to each other and to the dual memory controllers, as well as to the two Ultra Path Interconnect (UPI) links serving as the bridge to the partner chip (McCalpin 2021, footnotes 1 and 2). The 2D mesh also provides the PCIe connections to any peripheral components, such as the adapter that connects the node to the network. When thinking of the performance of a Frontera node as a whole, it is important to compare the memory bandwidth for the processors to the communication bandwidth between two processors on the same or different nodes. The situation is summarized in the diagram below.
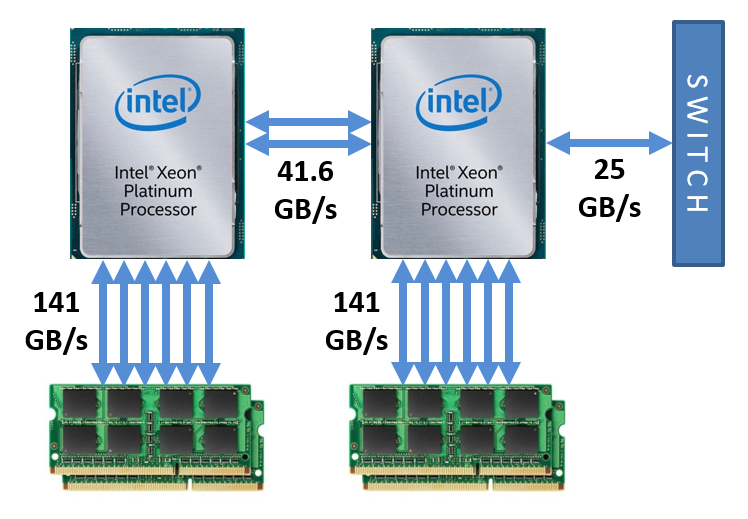
Here are the bandwidth details. In a Frontera node, the memory subsystem on each socket features six channels to DDR4-2933 DIMMs (141 GB/s peak rate) and two UPI links (41.6 GB/s full duplex rate) between sockets. Each processor's internal mesh includes bridges to PCIe: on one socket, a PCIe 3.0 x16 connection is occupied by a Mellanox ConnectX-6 Host Channel Adapter (HCA), leading to the InfiniBand (IB) network fabric. While the theoretical one-way peak rate for PCIe3 is 16 GB/s, the HCA limits it to 12.5 GB/s in each direction due to the intrinsic 100 Gbps speed of InfiniBand HDR100. Thus, the bidirectional bandwidth through the adapter is 25 GB/s.
Intra-node vs. inter-node communication
Even though UPI and InfiniBand communications are very fast, their bandwidth in Frontera is not as fast as the memory bandwidth. This suggests each processor should be viewed as a unified group of 28 cores with high-speed access to one socket's local memory, but with slower access outside of it. Following this line of reasoning, we can imagine designing a program for Frontera that [A] has relatively loose coupling between the two processors within a node, and [B] maintains even looser coupling to the processors on other nodes. The argument for [B] is strengthened by the fact that the latency penalty for venturing off-node can be far worse than the reduction in bandwidth, if many small messages must be communicated.
On the other hand, for large MPI messages—say, bigger than a megabyte—intra-node communication doesn't have as much advantage over inter-node communication as the diagram suggests. Not only is latency less important, but one or more copies of such messages must be made in local memory, in order to share them with the other on-board processor cores (Chai, Gao, and Panda, 2007). In general, however, intra-node communication is faster.
To handle intra-node communication on the one hand, and inter-node communication on the other, do we therefore need two levels of parallelism?
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)