Planning from the Start
The process of building a scientific application starts with a general model and ends with a specific piece of software. At each stage in the process, decisions or actions can be taken that can strongly influence the ultimate performance of the software, i.e., the speed at which it produces results.
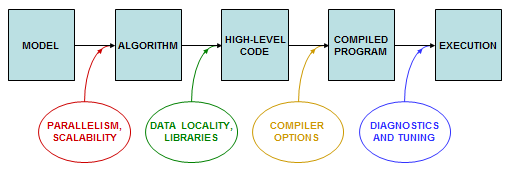
how to influence overall performance at each stage
From the very start, developers have choices to make in design and implementation to optimize their codes. Most important is selecting the set of algorithms that will be used to solve the scientific problem. Often this decision has the greatest impact on parallel efficiency and scalability.
It may not be intuitively obvious which algorithm is best. A method that is highly efficient on one or a few processors may not be optimal for a large-scale parallel system. For example, a simple numerical method that is relatively inaccurate on a modest grid might be the one that scales most readily to thousands of nodes, permitting computations to be run on much finer grids.
A code usually decomposes into sub-algorithms, and each of these may possess variants with different scaling properties. For each sub-algorithm, it can be useful to consider whether an alternative exists that, even though less efficient for small numbers of processors, scales better so that it becomes more efficient for large numbers of processors. Generally it is best to consider these questions in the first stages of design, when the top level is constructed. Codes that run best at scale are typically those in which the parallelism has been identified and expressed at the highest possible level.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)