CPUs and Processors
Prior to 2022, Stampede2 (predecessor to Stampede3) offered approximately 18.2 PF of peak floating-point throughput. Of that, 12.8 PF was provided by the Xeon Phi (KNL) compute nodes, which featured a large number of CPU cores with augmented SIMD capability—similar to GPUs. The remaining 5.4 PF was provided by the Skylake Xeon (SKX) compute nodes, which had fewer, but faster, cores. The KNL and SKX processors shared a similar architecture, though with quite different sets of design tradeoffs, and they shared similar (but not binary-compatible) 64-bit x86 instruction sets.
One key similarity between the KNL and SKX architectures is that they both get a huge boost to their floating-point performance by having a large number of cores with 2 vector units per CPU core. This is now true of nearly all modern processors, which may possess even more vector units per core. Because these vector units function in largely similar ways, the concepts and techniques discussed in this Cornell Virtual Workshop roadmap apply to nearly all processor types.
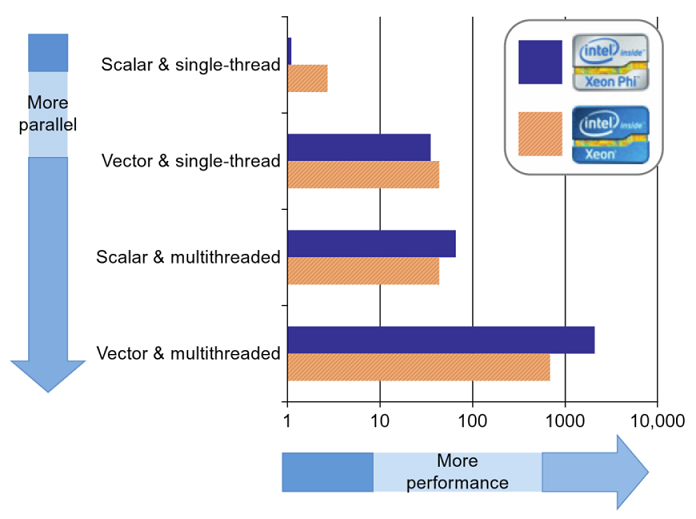
The above figure illustrates the relative importance of parallelism to the performance of KNL and SKX. But regardless of the exact balance between vector units and cores, the purpose of vectorization is to utilize the parallel SIMD hardware that is available on a core. The purpose of multithreading is to utilize all the cores in the processor.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)