Fault Tolerance
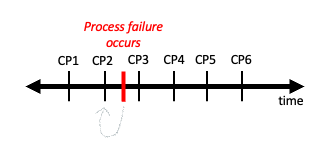
Leveraging multiple GPUs to train neural networks comes with many challenges. One of the biggest is what happens when GPUs fail due to many potential issues (overheating, old system wears out, viruses, etc.). Fault tolerance is the ability of a system to maintain operation despite one of its components failing. One way to combat component failure is via checkpointing. In checkpointing we periodically save the state of our application (in the case of deep learning the current weights of our model), so that if a process failure occurs we can resume our application from the previous checkpoint (See Figure 2).
Next, we will talk about torchrun, PyTorch’s tools for launching distributed training that will handle fault tolerance via checkpointing for you.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)