Introduction to DDP with PyTorch
Krishna Kumar
The University of Texas at Austin, Chishiki-AI
5/2024 (original)
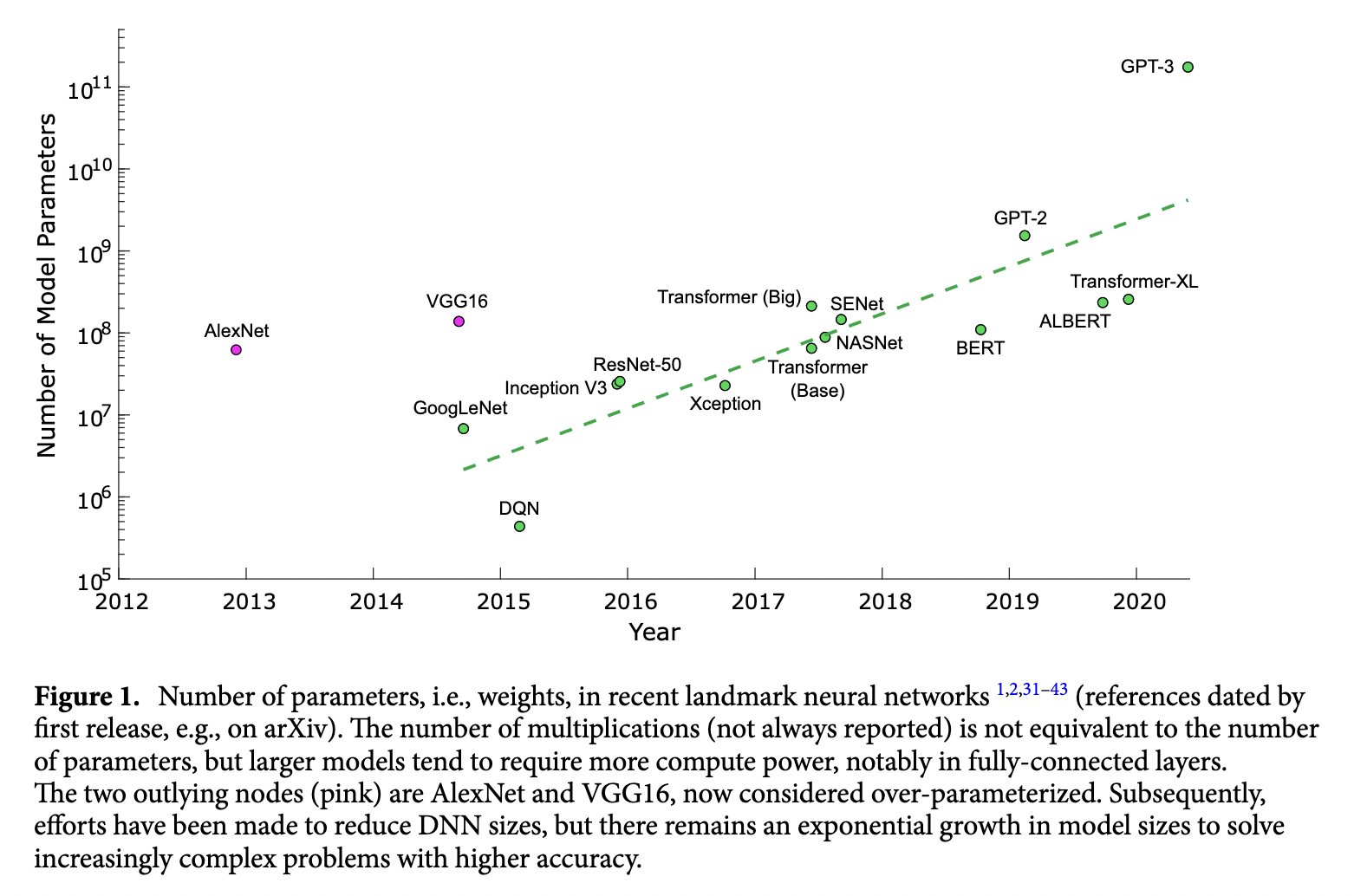
Training neural networks is an expensive computational task that is getting even more expensive. In the figure below, we can see how the size of neural networks has grown exponentially over time. As the number of parameters increases the training times also increase. Using multiple GPUs is critical for training deep learning models.
The aim of this tutorial is to introduce the basics of parallel computation and implement a method called Distributed Data Parallel with PyTorch that runs on one node with multiple GPUs. Specifically, we will cover the following material:
Introduce parallel computing at HPC centers
Introduce the basics of Distributed Data Parallel (DDP)
Highlight major code modifications needed to scale non-distributed model training scripts with PyTorch’s DDP
Modify code from a simple MNIST Classifier example to run at scale using DDP
[2] URL: https://arxiv.org/abs/2006.15704
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)