Distributed Data Parallel (DDP)
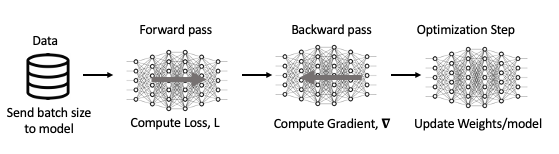
Before we dive into how DDP works, let’s review what the typical training process entails using a single GPU. One step in the process of training a neural network consists of the following:
- Receive an input batch and complete a forward pass to compute the loss associated with your current weights
- Based on (1), complete a backward pass where gradients associated with your current weights and batch are computed
- Update weights based on gradients from (2) and selected optimization algorithm
Steps 1-3 described above and visually represented in Figure 6 are repeated iteratively until a minimal loss is achieved or computing resources run out.
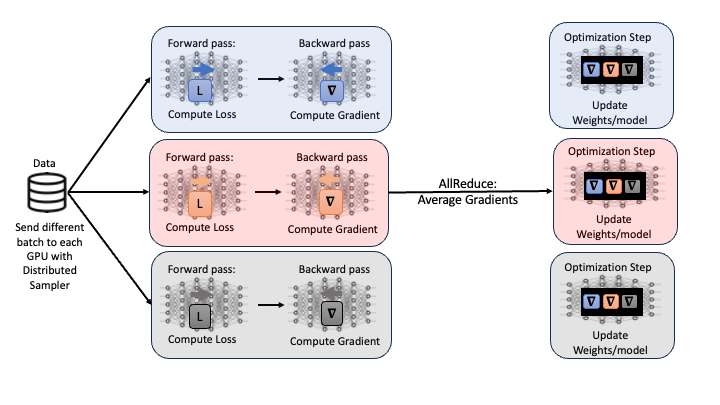
One popular technique to scale the training process, or modify the training process so that we are leveraging multiple GPUs, is called Distributed Data Parallel (DDP). In DDP, each GPU being used launches one process where each GPU contains a local copy of the model being optimized. Then, a different randomly generated batch of data is sent to each GPU and the forward and backward passes are computed.
One option for the next step would be to update model weights on each GPU. However, this would result in different model weights as the loss and gradients computed should all be different on each GPU as different data was used. Instead, all gradients are synchronized by averaging gradients from each GPU and sent back to the individual GPUs via an Allreduce operation. The Allreduce operation is where the synchronization, data movement and collective communications come into play in DDP:
- Synchronization: wait until all GPUs have computed their gradients
- Data Movement: move data so the average gradient can be computed and then broadcast back to all GPUs.
- Collective Computation: averaging gradients from each GPU
Performing the Allreduce operation of the gradients ensures that when the weights are updated on each GPU, the models remain equivalent. This process is repeated throughout the training process with DDP. A visual representation of one iteration of DDP is shown in Figure 7.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)