Database Normalization
Database normalization is a process which pushes the design of a relational database which avoids anomalies—situations where inconsistencies exist within the database—arising from the common database actions INSERT, UPDATE and DELETE. Briefly, these are:
- UPDATE anomaly: data in one or more columns in one or some rows is updated to a new or correct value, but the same data in other rows are not updated, resulting in data inconsistency
- INSERT anomaly: data cannot be entered because of incomplete information; for example, a measurement cannot be entered because the full information on the generating instrument is not available with the measurement. Note that this can in principle be solved by the use of NULLable columns, but needing a lot of those when the data are to be filled in later maybe be a sign that the database is not well-designed for its purpose
- DELETE anomaly: deleting data, such as deleting a person's name from a list of observations, causes deletion the observations themselves. Again, this can be avoided with NULLable columns but needing to do that a lot can be another sign of a poorly designed database
Database normalization reduces the likelihood of these anomalies at design time. To work through the normalization process, we use a simple, invented example of data taken from weather stations. We first see the data in a non-normalized form, perhaps in a spreadsheet or in some programmatic data structure such as a Python list-of-lists or some other array type. In order to illustrate all of the normalization steps, the example is probably rather worse than we'd expect to encounter in the wild, but also there would generally be many more columns of data as well, which we omit in the interest of illustrating principles with less cluttered visualizations.
When designing databases, we list the columns rather than the data contained within (there's no data yet) and before creating the database we will also specify column data types and whether they accept NULL values. Here is the list of fields for each data point:
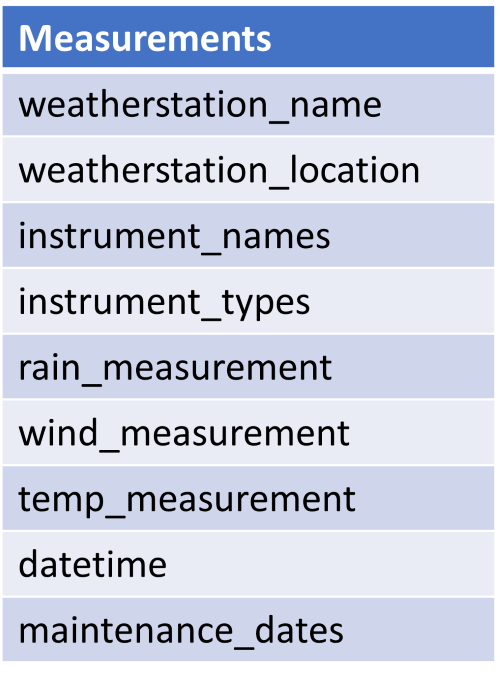
You may immediately see some issues with this structuring of the data, but we'll pick out some particularly important ones as we progress through the normalization process, to first normal form (1NF), second normal form (2NF) and then finishing in third normal form (3NF). There are three or four additional normal forms defined, but in general most database designers stop at 3NF (and, as we shall see, some may then step back from normalization a bit). This is a simple, invented model; often there will be a lot more sophistication to the data (a complete maintenance record for the instruments, with one or more additional tables, for example), but this model is chosen as illustrative of the concepts which are applied when normalizing a relational database.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)