Keys and indexes
Keys specify rows or groups of rows; in addition to being very helpful in achieving clean design and consistency of stored data, they are also often part of the specification for retrieving data given in database queries. When executing a query on a large database, it is often important to index some of the columns which feature in the constraints imposed on the query for the same reason a book index makes finding relevant pages easier. For example, if we are looking for all stars with a given spectral type, an index on the spectral_type column would allow quicker selection of only the relevant rows, instead of individually searching every single row.
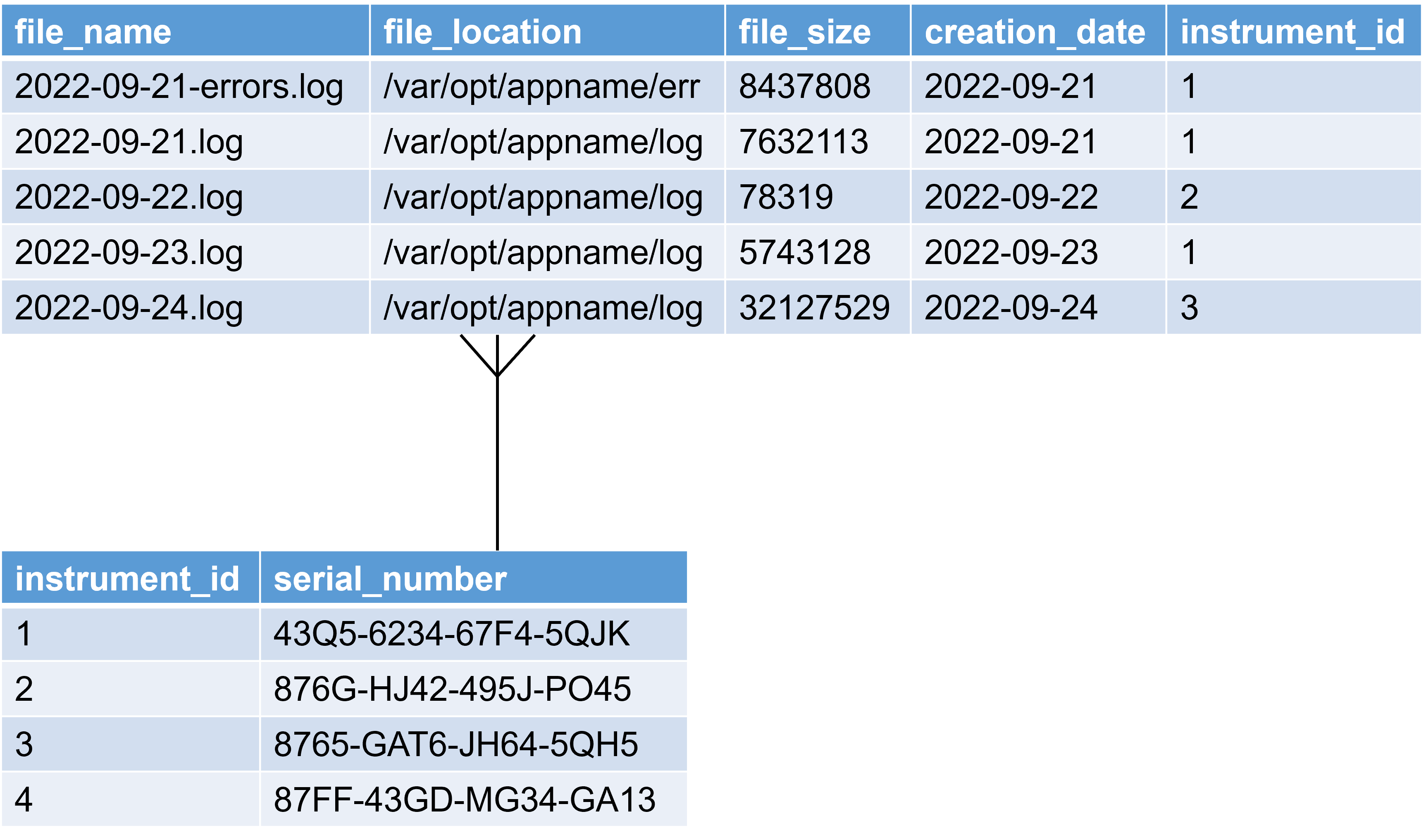
We now return to an example from earlier—files written into our file system by some instruments—but now we also specify that our files are written by different instruments, each of which has a serial number (which might be specified as a CHAR(19), in this case, four groups of four alphanumeric characters with three dashes), which we might use if communicating with the manufacturer. We could include all that information in one table, but in general we don't (for reasons explained when we discuss designing databases) and would record the files information in one table, and the information about the instruments in another. We will refer to these tables as we discuss database keys and indexes, and the meaning of the asymmetric connector between the two will also be explained. Note that, in practice, the instruments table would include more columns than are shown but here we limit ourselves to two columns of most interest for explanatory purposes.
Keys
A key is a value, or set of values, which allows identification of a row or rows. The main types are Primary Key and Foreign Key.
The most important type of key is the primary key; this is the column or columns which uniquely identifies a given row in a table and in most cases, every table should have one. A primary key column cannot allow NULL values and the primary key of a given row cannot be duplicated in any other rows. In the figure above, although the file_name column might appear to be a good candidate for primary key, that would mean we could never have two files with the same name. In practice, a compound primary key would be better, of file_location and file_name (if there were multiple file systems, of course, a third column in the primary key for listing that might be required).
Often, it is convenient to just have an integer id column which auto-increments each time a new row is entered; this sort of key is very common and is called a surrogate key; their name often includes "id" or "_id" and you will probably see them in more relational databases than not; in our example, the instruments table has an instrument_id column which is a surrogate key. We could also have used a file_id column in the files table. Note the limitation of a surrogate key: they contain no semantic information whatsoever, unlike the compound primary key of file_name and file_location. Even assuming that higher numbers in a surrogate key column correspond to later additions to the table can be risky! The opposite of a surrogate key is a natural key, which in the files table we did with file_location and file_name. If a surrogate key is used, the information which might have comprised a natural key is often also included in the table; sometimes we find the surrogate key value by querying on natural key information.
Foreign keys deal with the relationship between tables. In essence, a foreign key requires that an entry in one table exists in another table; for example, every instrument_id in the files table must correspond to an entry in the serial numbers table. In practice, this would both encode a requirement that every instrument's details were recorded (assuming that serial_number doesn't allow NULL entries) and also allow query-writers to access the instrument serial number associated with each written file even though it's not in the files table itself. It can be seen that this is a many-to-one relationship; many files can be written by any given instrument. The end of the connector with three legs is the "many" side of the relationship and the unique side, which is fixed on the primary key of the serial numbers table. Other visualizations of relational databases may represent foreign keys differently, for example, with a key at the "one" end and an infinity symbol at the "many" end.
Indexes
Consider a case where we wanted all of the files written on a given date. We might expect them to be scattered throughout the files table, amongst tens of thousands to millions or more rows. It would be inefficient to search each row and check if it had a given creation_date for the same reason it would be inefficient to read an entire software manual to find the pages which mention a given topic of interest but, without some help, there would be no other choice. With databases, as with the software manual, this is where indexes are helpful.
A database index is what it sounds like; defined on a column or columns, it stores the indexed column values sorted by the value in the column coupled with a locator associated with each row (analogous to how a software manual's index stores topics alphabetically—these are the sorted column values—along with page numbers which are like the locator). This will make any searching on that column's values much quicker.
Which columns should be indexed? Why not just index every single column? There are performance and space implications; a column index obviously consumes space as it duplicates, with a different sort order, some of the data in the source table. In addition, every time data are inserted, updated or deleted, the indexes have to be updated as well, which has a computational cost and takes additional time. Primary keys are automatically indexed, and other columns which should be indexed are those on which queries are often made. The group of frequently-queried columns includes columns containing foreign keys, like the instrument_id column in the files table; finding the serial number to go with each file would require a general search through the files_table to match across to each serial number, but an index will make this process (called a JOIN in SQL) much quicker. Finally, there are some additional options for indexing which are RDBMS-specific, such as covering indexes; consult your RDBMSs' documentation for specific details.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)