CUDA Program Structure
A CUDA program relies on two components: the host and one (or more) GPU device(s), which we will refer to as the device. The host executes host code, which is defined as code that runs exclusively on the CPU, and similarly, the device executes device code, or code that runs on GPU devices. A typical CUDA program starts by executing host code, and at a certain point, calls a kernel function to signal the GPU to execute device code.
It's worth pointing out that device code execution is asynchronous with host code execution, meaning the host continues executing its code after a kernel call. For that reason, CUDA provides explicit and implicit synchronization of host and device code, which will be discussed in future pages.
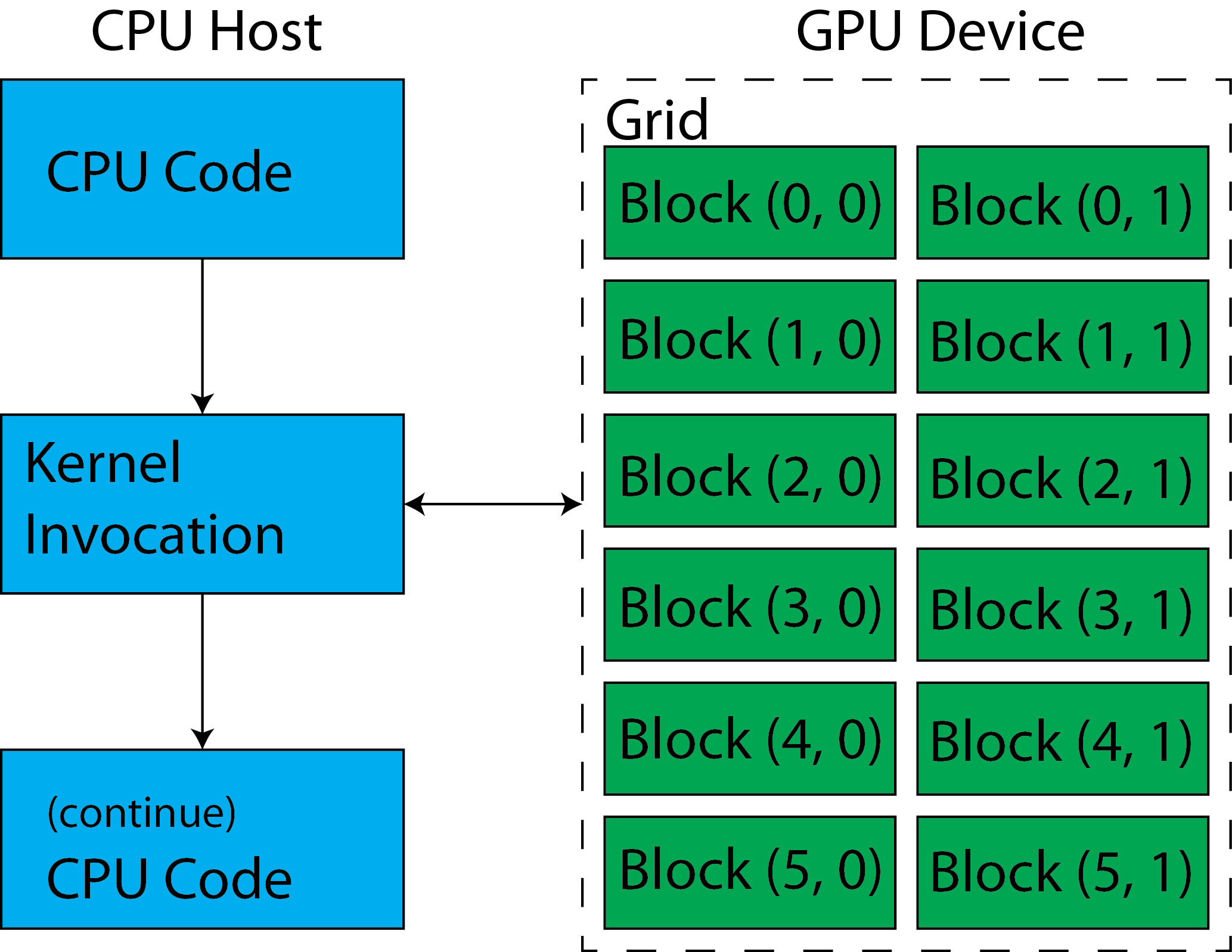
By calling the kernel function, the CUDA program launches a number of threads on the device, all of which concurrently execute the kernel function. These threads are organized into thread blocks, also referred to as blocks, which are organized into a grid. A kernel call launches only one grid, while its blocks and threads may be logically arranged into multi-dimensional structures. The limit of threads per block and blocks per grid is determined by the GPU device and its Compute Capability.
The figure shows the logical structure and execution flow of a CUDA program.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)