Threads, Blocks, and Grids
CUDA programs are intended for data that can be processed in parallel. In properly implemented CUDA programs, data are partitioned into small chunks, each of which is processed by a unique thread on the device. All threads execute the same device code as instructed in the kernel function. Threads are organized into thread blocks, and thread blocks are organized into a grid. This is the basic concept of CUDA programming.
Threads, Blocks, and Grids
In CUDA, a single call to a kernel function launches a grid. A grid consists of thread blocks, abbreviated as blocks, and blocks consist of threads. Grids, blocks, and threads have different properties and purposes. The device code describes the instructions for a single thread, and it is executed by all threads. This programming model, known as thread abstraction, has the advantage of scalability since all threads essentially execute the same piece of code.
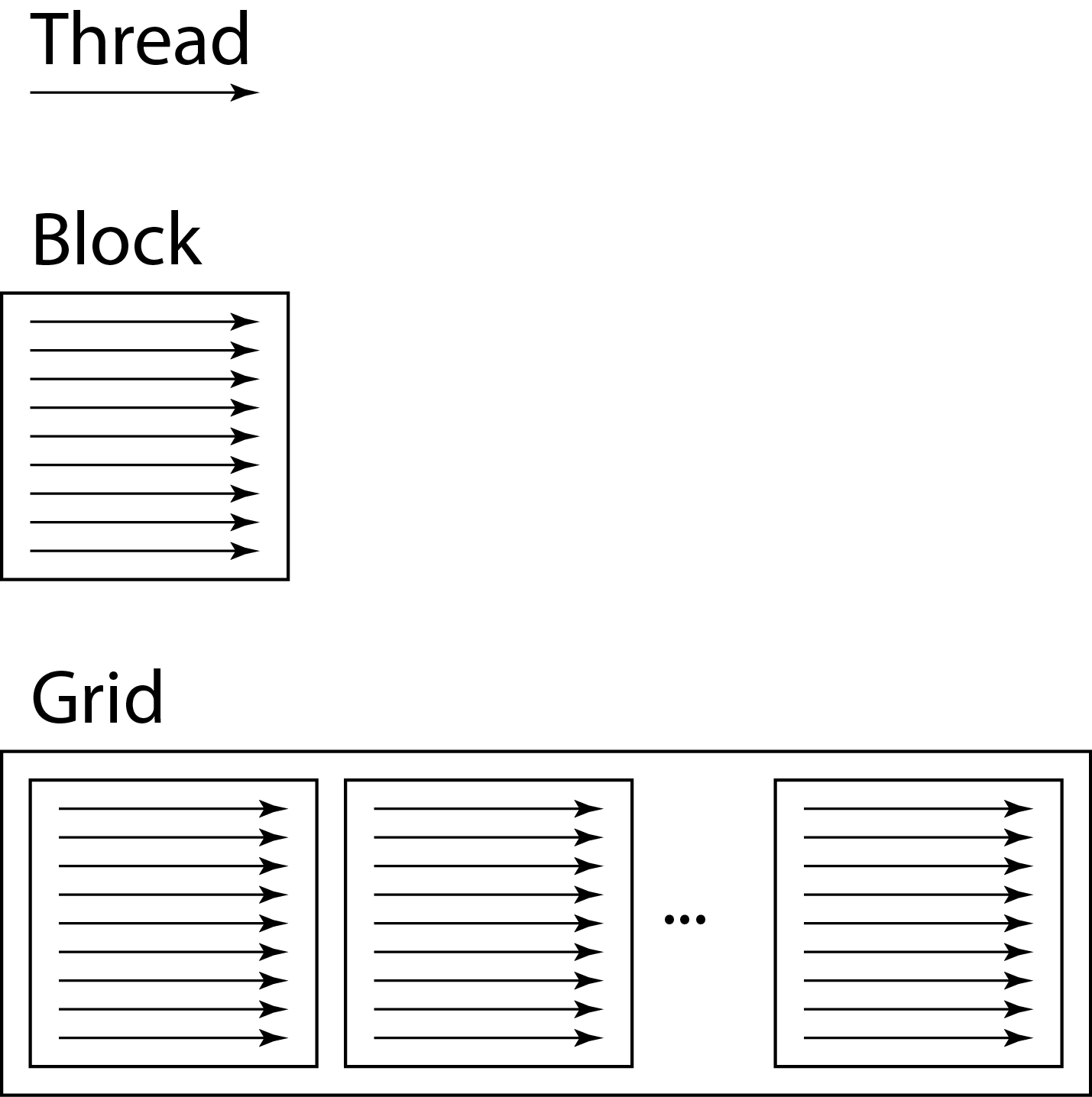
Threads
Threads are the smallest unit of execution in CUDA programs and execute the code defined in the device code. Threads of the same block all run on the same Streaming Multiprocessor (SM), which allows them to share certain resources of the SM, such as shared memory. Threads of the same block are also capable of synchronizing within the block to ensure the correctness of the program. But threads from different blocks are completely independent in execution; the only shared resource they have is the global memory of the GPU, which is accessible to all threads in the grid. The reason for threads to use shared memory is that it is frequently used to optimize CUDA code, as we will see in later topics.
Block
Thread blocks, or just blocks, execute independently of each other. When a kernel function is called and a grid is launched, the blocks within the grid are assigned to SMs. The GPU device may have several dozen SMs. An individual block cannot be distributed across multiple SMs. The assignment of blocks to SMs depends on the CUDA scheduler and the Compute Capability (CC) of the device. For example, the NVIDIA T4 Tensor Core GPU, which has a CC of 7.5, can assign a maximum of 32 blocks to each of its 40 SMs. In addition, the compute capability of the GPU determines the maximum number of threads per block.
Grid
A grid, also referred to as an active kernel, is a collection of blocks launched with a single kernel call. One kernel call launches one grid, but multiple grids may exist in a CUDA program simultaneously. Each grid has its own independent workspace. The maximum number of grids that can be launched is determined by the CC of the GPU device. For example, the NVIDIA T4 Tensor Core GPU, which has a CC of 7.5, can have 128 grids.
Parallelism
The independence of blocks and kernels allows CUDA to be more scalable and more flexible. It allows CUDA to support the following modes of parallelism:
- Data parallelism, at the thread level - Different threads, each running on a separate "CUDA core", execute the same set of instructions on different data
- Data parallelism, at the block level - Different thread blocks, each running on a separate SM, execute the same set of instructions on different data
- Functional parallelism, at the grid level - Different grids, all running within the GPU device simultaneously, execute different kernel functions or tasks in distinct CUDA streams (to be described later)
Properly speaking, the way the device code executes on a GPU is concurrent—i.e., potentially parallel—rather than strictly parallel. All the threads in a block may not be able to run at the same time on an SM; the SM will typically have to execute them in batches (or "warps"). Likewise, some of the blocks might have to wait until an SM becomes available. The umbrella term for parallel processing in CUDA is kernel parallelism, or stream processing. This term covers all the levels noted above.
Block Index and Thread Index
In a CUDA program, the threads need to know which data to process. If 10 chunks of data can be processed in parallel on 10 threads, each thread needs to access its own chunk. In addition, if the volume of the data to be processed is increased, the CUDA program should automatically adjust accordingly. Therefore, how are threads programmed to retrieve the correct data without hardcoding indexes?
CUDA automatically assigns a couple of variables to each thread. These variables are unique to each thread within the grid. The variables blockIdx and threadIdx contain the indexes of the thread and the block it's in. For now, we assume that the thread index and block index are both scalars (one-dimensional vectors), and can be accessed by threadIdx.x and blockIdx.x. In reality, threadIdx and blockIdx can be multi-dimensional vectors for programmers' convenience. This will be discussed in later topics.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)