Concurrent Streams
What is a CUDA Stream?
While CUDA is designed to be as parallel as possible, it requires the programmer to define the high-level parallelism through the use of streams. In the context of CUDA, a stream refers to a single sequence of operations executed in issue-order on a GPU device. Every kernel is enqueued and launched on a stream, even if we did not specify it. If the stream is not defined at kernel invocation, the default stream, known as the NULL stream or stream 0, is used. The default stream is special, and its main uses will be discussed in this topic.
Once a kernel is invoked in a stream, it's placed in a "first in, first out" queue of that stream. The device launches a grid of blocks of threads to execute the first kernel that appears in the queue. After the kernel completes, a grid is launched for the next kernel in the queue, and the process repeats until all the kernels in the queue are finished. Kernels can be enqueued to streams at any time through kernel invocation.
But then, how do streams enable parallelism? By default, all streams, except the default stream, are independent, meaning they do not communicate with each other. As long as resource permits, streams will execute their respective kernels in parallel with other streams. For example, we can invoke n independent kernels in n streams to allow all the kernels to be executed simultaneously. However, unlike kernels placed in a single stream, there is no guarantee that the kernels are completed in any particular order. To coordinate the order of kernel executions between streams, CUDA provides synchronization mechanisms, which are discussed on the next page.
To create and use streams, one must declare a cudaStream_t variable, initialize a stream on it with cudaStreamCreate(), and invoke kernels while passing the stream variable as the fourth parameter in the execution configuration. (Recall that the third parameter is the amount of shared memory to allocate dynamically for the kernel.) Streams have to be destroyed at the end of the program with cudaStreamDestroy().
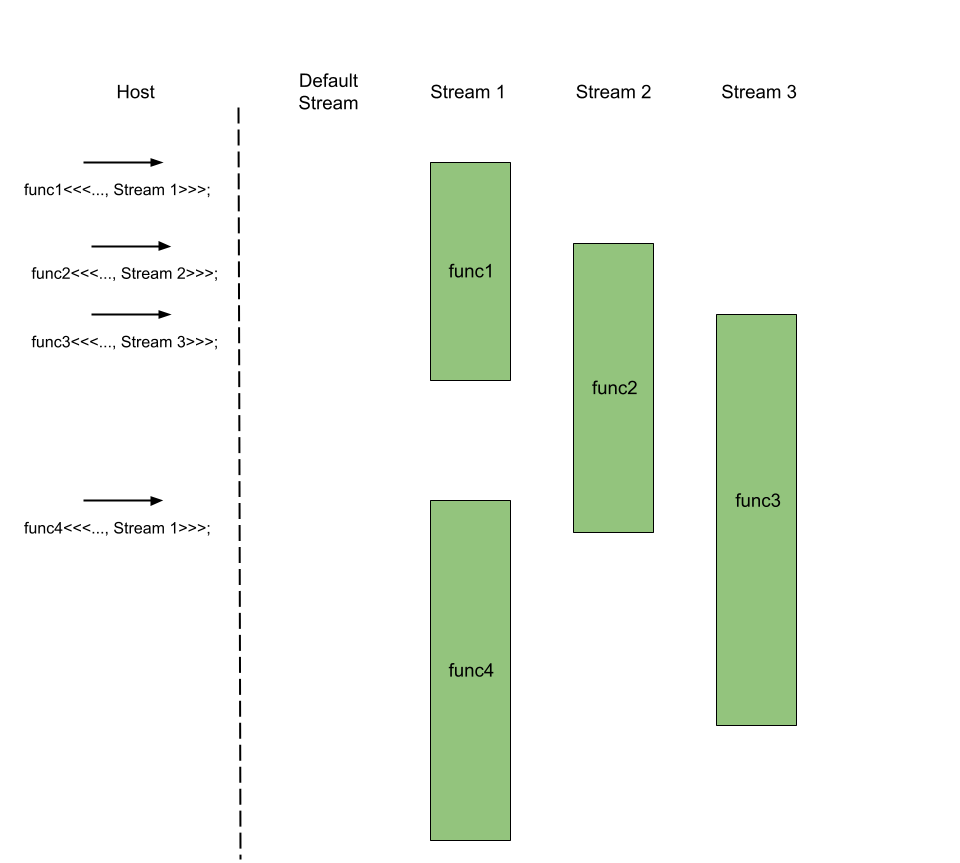
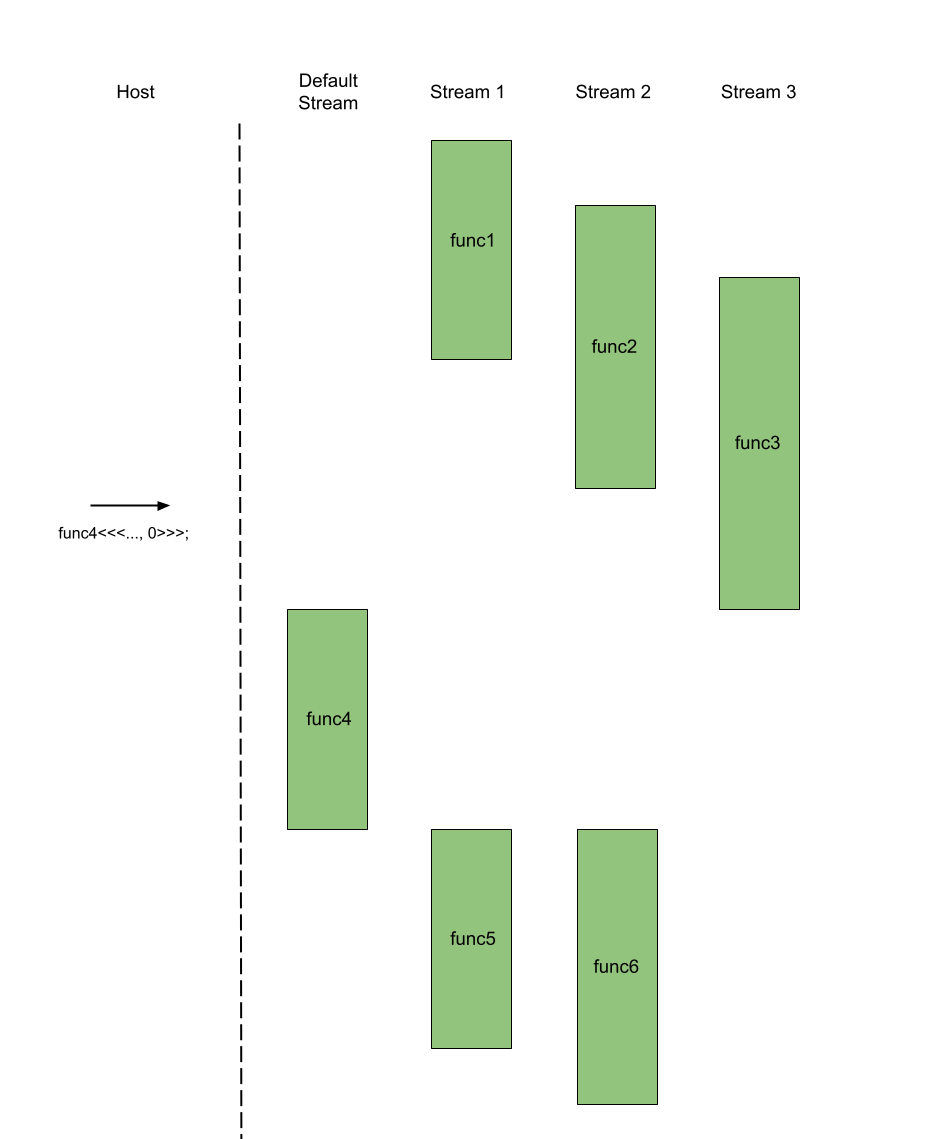
The default stream is the exception to the rule. The default stream cannot be run concurrently with any other streams. That means when a kernel func is invoked on the default stream, the default stream is blocked and waits for the non-default streams to finish their kernels that were invoked before func's invocation. Conversely, any kernel invocations on the non-default streams made after func's invocation must wait until func completes on the default stream, despite being in the queue of their respective streams. In essence, The default stream is a synchronization method for all the non-default streams.
Asynchronous Memory Transfer
As a consequence of CUDA's memory transfer model, memory transfer with cudaMemcpy occupies both the host CPU and the default stream of the device, restricting the device to only one synchronous memory transfer at a time. Alternatively, though, memory can be transferred through non-default streams, bypassing this restriction completely and allowing the device to perform asynchronous memory transfers.
The core idea of asynchronous memory transfer, cudaMemcpyAsync, relies on pinned memory and non-default streams. Pinned memory is not swapped to the disk, allowing the system to use Direct Memory Access (DMA) transfer between the host and device, thereby bypassing the need for the host CPU. By using non-default streams, we avoid the default stream completely, which prevents any blocking behaviors on the non-default streams. Neither the host CPU nor the default stream is involved in an asynchronous memory transfer, enabling the CPU and streams to continue their code execution. If optimized correctly, asynchronous memory transfer reduces the total time to complete a set of kernels.
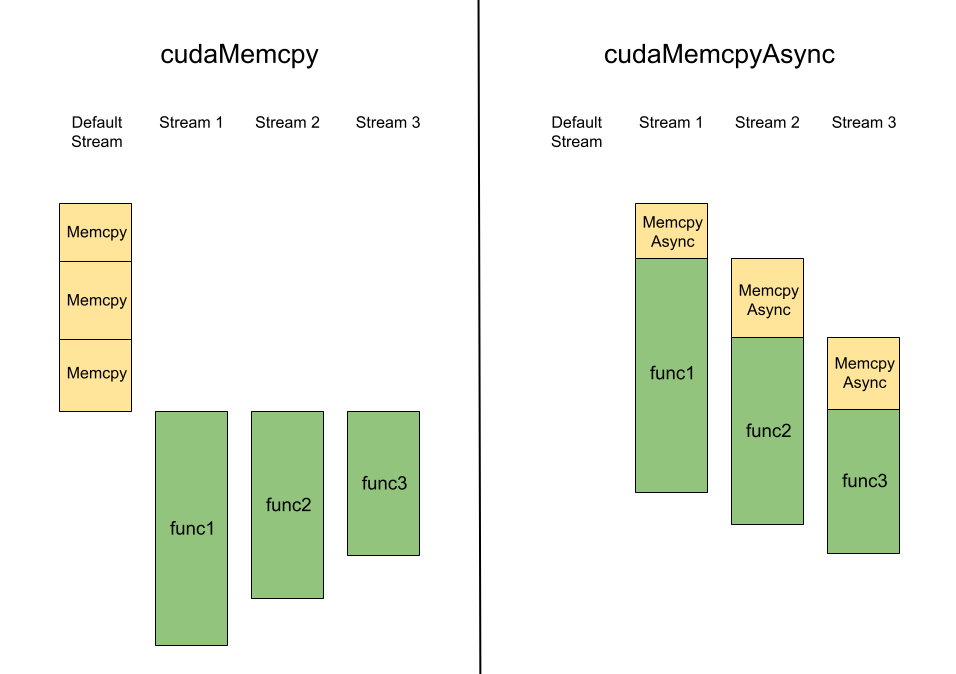
cudaMemcpy operations on the default stream: during copying, the non-default streams are blocked. The right side shows how the same timelines are affected by modified code with cudaMemcpyAsync operations on just the non-default streams: they don't block each other.
Here is a pseudocode of asynchronous memory transfer:
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)