Synchronization
Since there are many parallel components in a CUDA program, there are naturally different types of synchronization methods that apply to these components. Below, we will discuss three methods: host-side synchronization, device-side synchronization, and thread-level synchronization.
Definitions of Synchronization
The definition of synchronization is the act of bringing two or more processes to known points in their execution. When a process waits for another process to reach a certain point before continuing, the (former) process is blocked. This definition of synchronization is a broad one in CUDA's context, as there are multiple processes running in parallel, and we must distinguish what exactly is being synchronized.
Host-Side Synchronization
Throughout a CUDA program, it's often necessary for the host to synchronize with the device or with a specific stream. For example, the host must wait until all kernels are completed before retrieving the output data or launching new kernels. In any case, the host executes a specific line of code, after which it waits for the device to finish its specified task. We consider this to be host-side synchronization or blocking the host.
Host-side synchronization can be achieved by using the cudaDeviceSynchronize() function and, interestingly, the cudaMemcpy(...) and cudaFree(...) functions. For all these functions, the host cannot continue until the device executes all the currently queued kernels in all the streams. While these functions have other purposes, they implicitly synchronize the host with the device. Additionally, one can use cudaStreamSynchronize(stream) if the host needs to wait only for a specific stream.
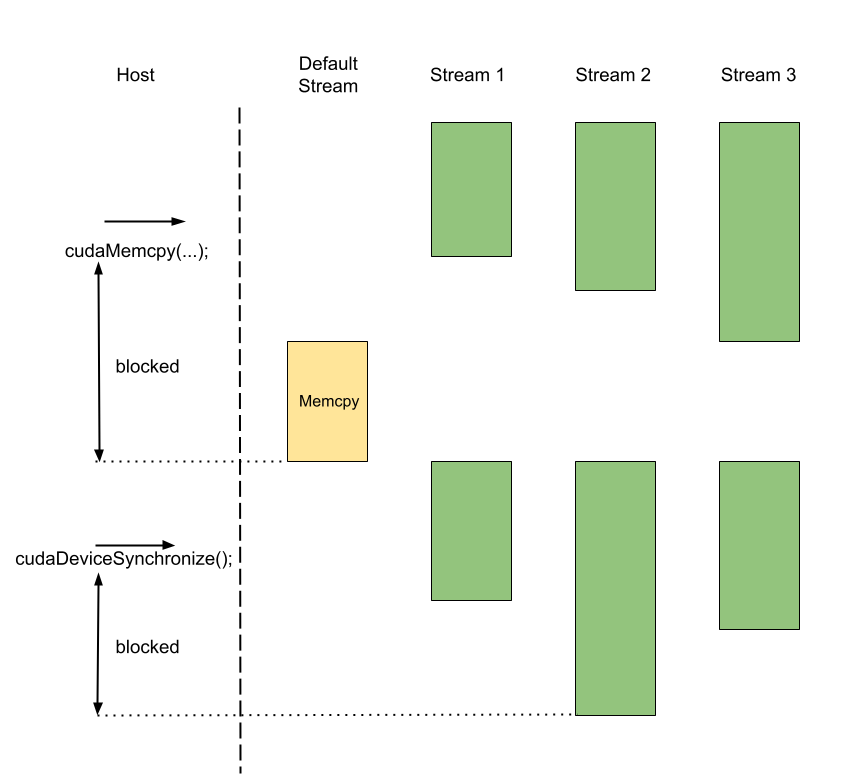
cudaMemcpy(...). Once copying is complete, new kernels can start on the streams. The host then synchronizes the streams explicitly with cudaDeviceSynchronize(); the host and all streams must wait for the slowest stream, Stream 2, to finish.
Device-Side Synchronization
On the device side, non-default streams can synchronize with other non-default streams, and the default stream can synchronize all of the streams. Note that device-side synchronization will not dictate the behavior of the host (the converse is false).
Any kernel invoked on the default stream blocks the default stream until the active kernels in other streams have completed. Any kernel enqueued afterward will likewise be blocked until the default stream completes. Thus, launching a kernel on the default stream is a method for synchronizing all streams. In addition, cudaMalloc and cudaMemcpy share the same behavior.
Streams can be synchronized with other streams through CUDA events, which are identified by variables of type cudaEvent_t, and by the functions cudaEventCreate, cudaEventRecord, and cudaStreamWaitEvent. A CUDA event is a synchronization marker that can be recorded by streams and waited for by streams. Once an event is recorded by another stream, the streams waiting on that event may start their respective kernels. The entire process is as follows. First, a variable of type cudaEvent_t is declared and initialized with cudaEventCreate() in the host code. Then, the host calls cudaEventRecord() to instruct a stream, stream2, to record the event when it reaches certain place between the execution of its kernels. Likewise, the host calls cudaStreamWaitEvent() to instruct another stream, stream3, to wait for the event prior to the execution of its next kernel. When stream2 reaches the specified point, it records the event and continues with its next kernel. Meanwhile, Stream_3 has been waiting for the event and has been blocked from executing its kernels. When the event is recorded, stream3 is given the signal to continue with its kernels. Of course, like all CUDA variables, events need to be destroyed with cudaEventDestroy() at the end.
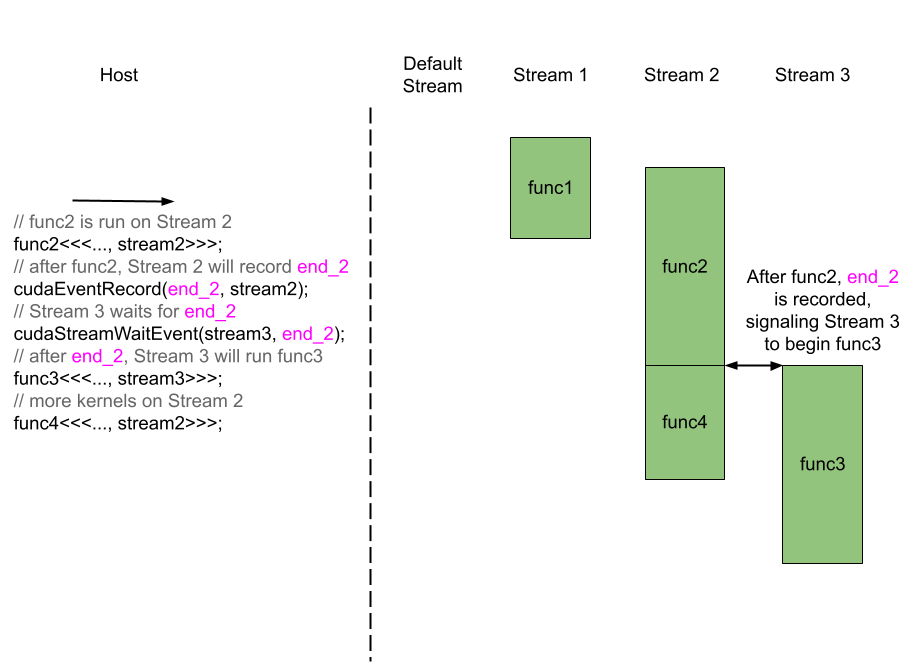
end_2; Stream 3 must wait for the event end_2 before it can run func3.
Thread-Level Synchronization
Threads can be synchronized with other threads within the same block. If a thread uses a variable that is updated by another thread, then the order of these threads must be specified, or the result will be unpredictable. To prevent threads from executing lines in the wrong sequence, one can use __syncthreads() to ensure that all threads within the block reach the line where __syncthreads() appears, before continuing. An important note is that all running threads must reach the same __syncthreads(); otherwise, if the line __syncthreads() becomes unreachable to a thread that hasn't exited, it causes unexpected errors.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)