Coalesced Memory Access
Coalesced memory access or memory coalescing refers to combining the global-memory accesses from some or all of the threads in a warp into a single memory operation. It is most easily achieved when the overall request brings in data from consecutive memory addresses starting on a good memory boundary. When all 32 threads of the warp are involved, this type of request is equivalent to a loading a single cache line from the L1 cache, which can be done very quickly. This is why a GPU cache line consists of 32 single-precision words of 4 bytes, or 128 bytes.
But the data path in most kinds of RAM is no wider than 64 bytes, which means it takes multiple transactions with the global memory to fill a GPU cache line. NVIDIA arranges its GPUs so that every successive 32 bytes (8 single-precision words) of global memory can be accessed in one transaction. As a consequence, NVIDIA splits one cache line into 4 "sectors" of 32 bytes, where each sector can be filled independently from global memory. An an example, if a warp of 32 threads accesses 32 consecutive words in memory, and if the data are not in the L1 or L2 caches (an "L2 cache miss"), then it takes a minimum of four transactions with global memory to fetch all the data. However, it may take more than four, as the memory transactions must be aligned to certain memory addresses.
Memory allocated by cudaMalloc() is always aligned to at least 256 bytes, and this helps with the proper alignment needed for coalesced memory access. Even so, any of the following conditions in a program may result in an uncoalesced memory access, resulting in multiple memory operations:
- array indexing is not sequential
- memory access is sparse, e.g., it goes through structs
- memory access is misaligned, e.g., an array index is offset from the thread index
Sequential and Aligned Access
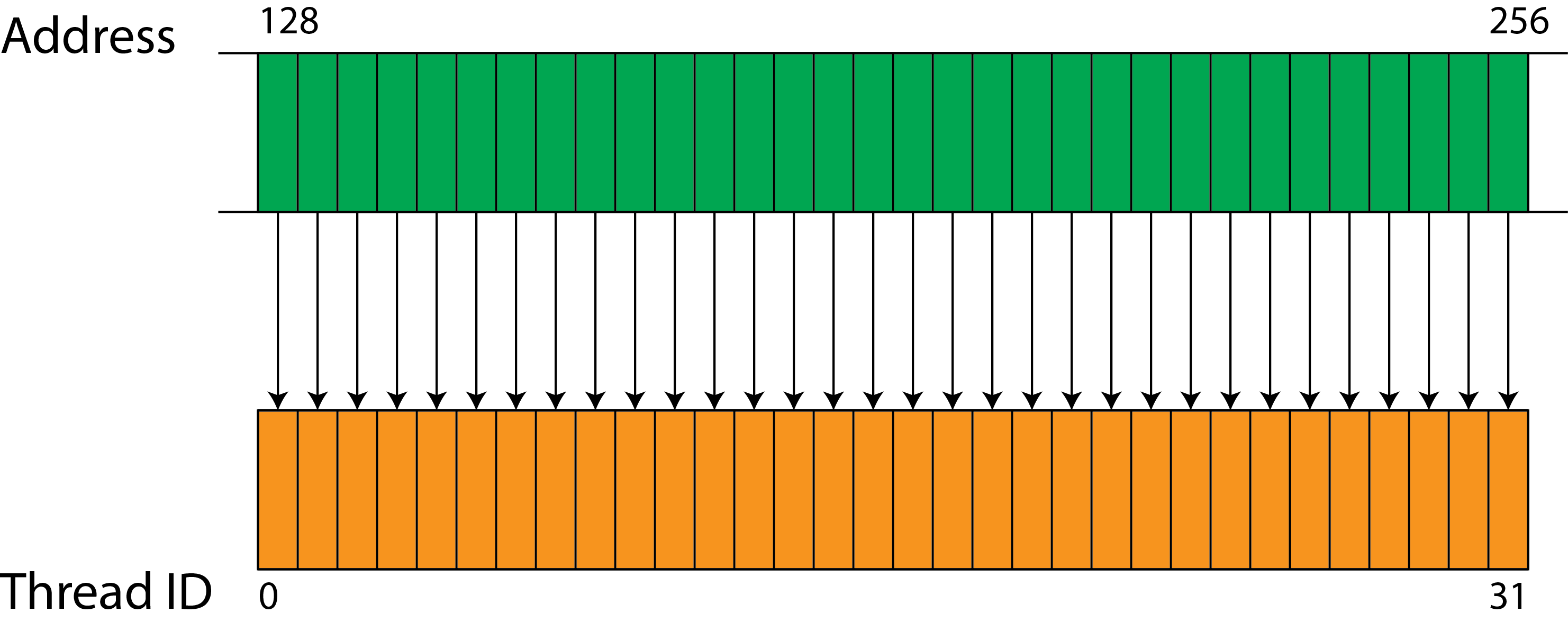
In the figure below, 32 consecutive threads access 32 consecutive words. The memory access is sequential and aligned, and is therefore coalesced. Only one operation is required to load all 32 words.
Aligned but Non-sequential Access
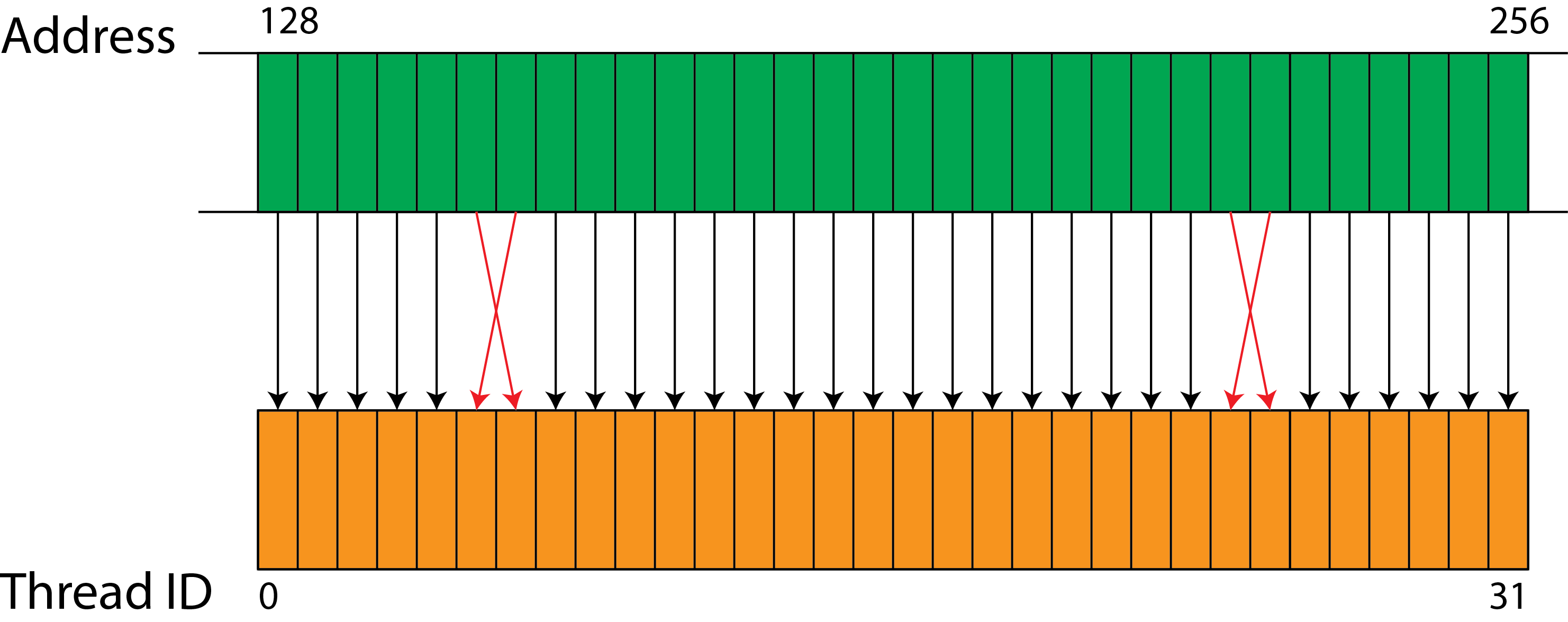
In the figure below, memory access is not sequential but aligned. In modern NVIDIA GPUs, such access patterns can still be combined into a single operation. However, this is not the case for earlier computing capabilities.
Unaligned Memory Access
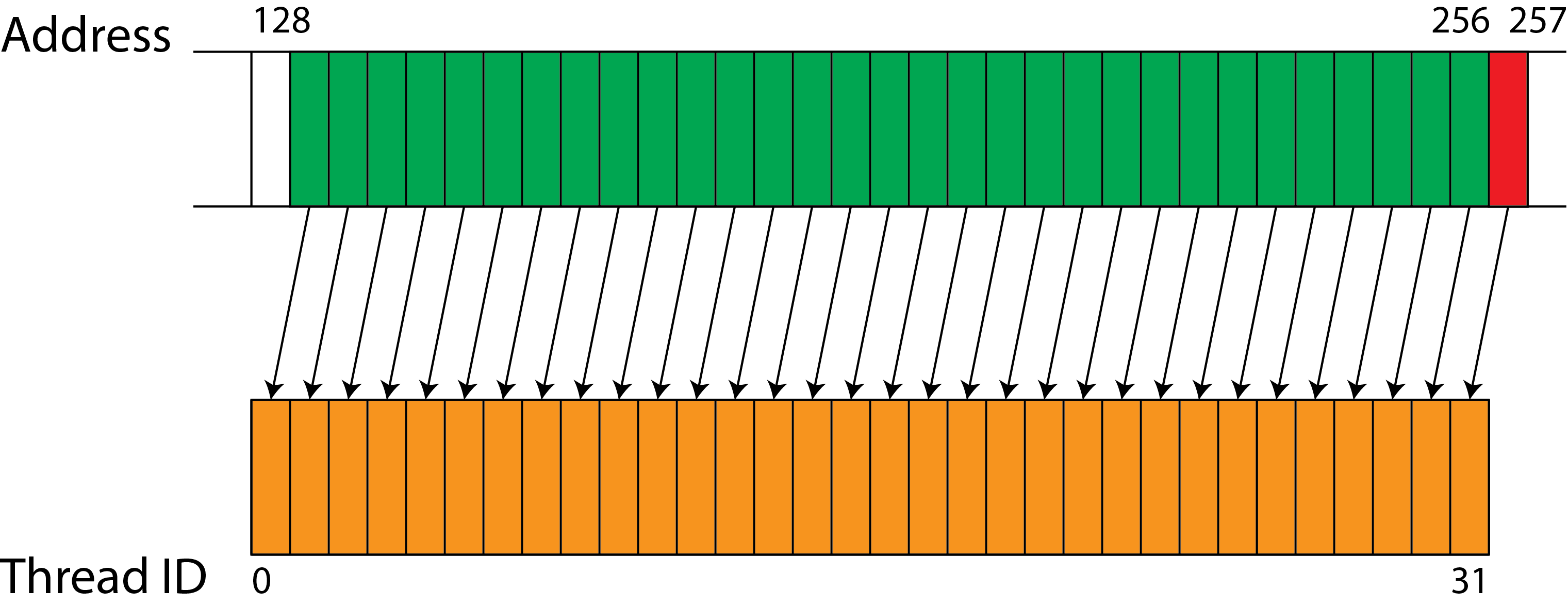
In the figure below, memory access is misaligned. Unlike the consecutive and aligned example, two operations are required to access the same number of words.
Code Examples
Uncoalesced memory access is difficult to recognize and may not affect the performance of your program by too much. However, there are cases where a program's memory access pattern significantly impacts the execution speed. Below is one such example. In the first kernel function, warps align with the columns of the two matrices, so that memory access is not sequential, and memory access is uncoalesced. In the second kernel function, warps align with the rows of the two matrices, so that the memory access is sequential, enabling coalesced memory access.
As a exercise, you can compile and run this program and compare see its performance.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)