SIMT and Warps
On the preceding page we encountered two new GPU-related terms, SIMT and warp. Let's explore their meanings and implications more thoroughly.
SIMT
As you might expect, the NVIDIA term "Single Instruction Multiple Threads" (SIMT) is closely related to a better known term, Single Instruction Multiple Data (SIMD). What's the difference? In pure SIMD, a single instruction acts upon all the data in exactly the same way. In SIMT, this restriction is loosened a bit: selected threads can be activated or deactivated, so that instructions and data are processed only on the active threads, while the local data remain unchanged on inactive threads.
As a result, SIMT can accommodate branching, though not very efficiently. Given an if-else construct beginning with if (condition), the threads for which condition==true will be active when running statements in the if clause, and the threads for which condition==false will be active when running statements in the else clause. The results should be correct, but the inactive threads will do no useful work while they are waiting for statements in the active clause to complete. Branching within SIMT is illustrated in the figure below.
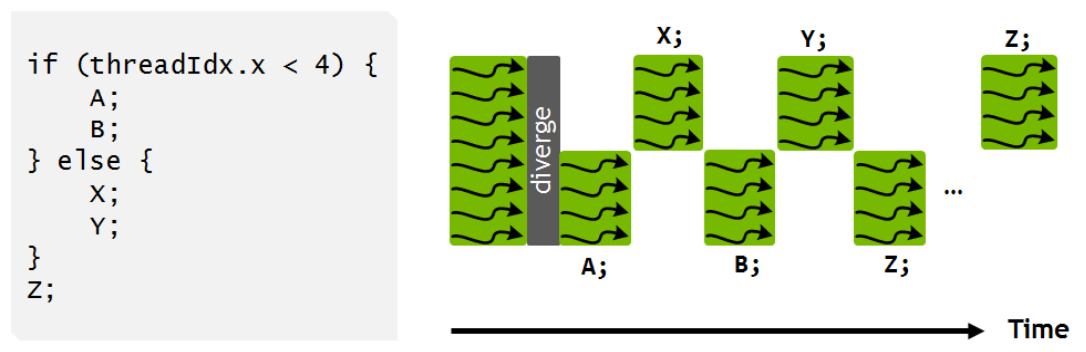
The figure, like several others in this topic, is taken from NVIDIA's Volta architecture whitepaper. It illustrates how an if-else construct can be executed by a recent GPU such as the Tesla V100 (or later).
Note that in NVIDIA GPUs prior to Volta, the entire if clause (i.e., both statements A and B) would have to be executed by the relevant threads, then the entire else clause (both statements X and Y) would have to be executed by the remainder of the threads, then all threads would have to synchronize before continuing execution (statement Z). Volta's more flexible SIMT model permits synchronization of shared data at intermediate points (say, after A and X).
It is worth observing that a form of SIMT also exists on CPUs. Many vector instructions in Intel's x86_64 have masked variants, in which a vector instruction can be turned on/off for selected vector lanes according to the true/false values in an extra vector operand. This extra operand is called a "mask" because it functions like one: it "hides" certain vector lanes. And the masking trick enables branching to be vectorized on CPUs, too, to a limited extent.
In contrast to how CPU code is written, SIMT parallelism on the GPU does not have to be expressed through "vectorized loops". Instead—at least in CUDA—every GPU thread executes the kernel code as written. This somewhat justifies NVIDIA's "thread" nomenclature.
Note that GPU code can also be written by applying OpenMP or OpenACC directives to loops, in which case it can end up looking very much like vectorized CPU code.
Warps
At runtime, a block of threads is divided into warps for SIMT execution. One full warp consists of a bundle of 32 threads with consecutive thread indexes. The threads in a warp are then processed together by a set of 32 CUDA cores. This is analogous to the way that a vectorized loop on a CPU is chunked into vectors of a fixed size, then processed by a set of vector lanes.
The reason for bundling threads into warps of 32 is simply that in NVIDIA's hardware, CUDA cores are divided into fixed groups of 32. Each such group is analogous to a vector processing unit in a CPU. Breaking down a large block of threads into chunks of this size simplifies the SM's task of scheduling the entire thread block on its available resources.
Apparently NVIDIA borrowed the term "warp" from weaving, where it refers to the set of vertical threads through which the weaver's shuttle passes. To quote the original paper by Lindholm et al. that introduced SIMT, "The term warp originates from weaving, the first parallel-thread technology." (NVIDIA continues to use this quote in their CUDA C++ Programming Guide.)
One could argue that the existence of warps is a hardware detail that isn't directly relevant to application programmers. However, the warp-based execution model has implications for performance that can influence coding choices. For example—as the figure above illustrates—branching can complicate the execution flow of a warp, if two threads in the same warp branch to different instructions. Thus, a programmer might want to avoid branching within warp-sized sets of loop iterations.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)