Why Hybrid? Or Why Not?
We have seen that hybrid programming entails the blending of two distinct types of parallel coding. One may therefore ask, is it worth the effort?
Why hybrid?
Adding a level of shared-memory parallelism brings the following benefits to the portion of the code that is contained within each node:
- Less need for domain decomposition - threads can work on the same data in parallel
- Smaller memory footprint - redundant copies of data can be eliminated
- Automatic data consistency - all threads of one process see the same memory
- Lower memory latency - no message passing needed to access data
- Ability to synchronize based on memory accesses instead of a barrier
Why not hybrid?
It may be a waste of effort to aggregate MPI processes into SMP components:
- Placing MPI parallel components on individual cores may actually run faster
- Threads may use caches inefficiently, if two or more try to write to the same cache line
- One MPI process may not have enough work to be subdivided effectively
Other possible motivations for hybrid
- Improved computational load balancing
- Reduced memory traffic, especially for memory-bound applications
The last point warrants further explanation. Message passing takes extra memory and uses memory bandwidth for communication between processes. But a hybrid application uses threads and shared memory within each node, so it can avoid some of these costs (though it may incur different kinds of memory costs).
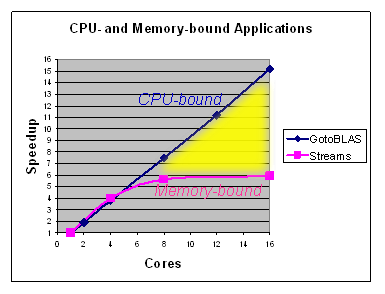
The figure below illustrates one possible benefit of reducing memory traffic in this way: improved scalability. Some applications are limited in their parallel speedup because they saturate memory bandwidth before all the available cores are fully utilized. Therefore, adding more cores makes no difference to their performance. Applications of this type are termed memory-bound. Hybrid strategies may help to move such applications further into the yellow region, i.e., closer to the CPU-bound line that continues to scale linearly with the number of cores.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)