Performance Testing
It's helpful to understand some of the performance characteristics of the RMA calls when figuring out how best to use them. RMA can be tricky to use, but we can learn a little bit about it by examining something simple, like the ping-pong benchmark. First, let's look at a simple code using standard sends and receives, which would go something like this:
This is just point-to-point communication where the manager process sends a message to the second process and then receives another message back. We loop through this many times to get a reasonable timing. The synchronization time is pretty low because the processes are kept in lockstep by the fact that all they do is send messages. However, we do still have 2 handshake delays in every iteration.
An RMA version of this same procedure would go something like this:
In this example, we've created a window around the data that we want the other process to get. Note that each process runs the window call separately. In the loop, we call fence then each process fetches the data from the other process. The point of this is to demonstrate that the two processes are passing the data simultaneously: we have essentially crossed the streams! It's a bit of a foolish example, as we have twisted the standard latency/bandwidth benchmark just to demonstrate RMA, but it nicely illustrates the idea of aggregating communication with minimal synchronization and avoiding lots of handshaking. Of course, we can't show this example without at least a peek at what the timing looks like!
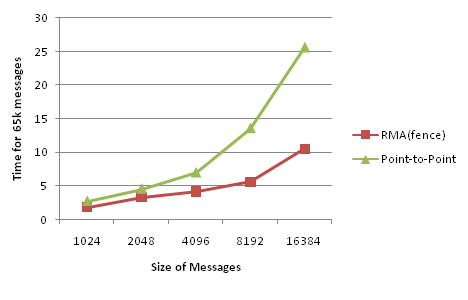
In the above graph, lower is better, meaning that it took less time to move data around using the RMA methods. As mentioned, the results should be viewed skeptically, as a lot of the speedup could have been obtained with two-sided, non-blocking communication calls. Recall that in the original code, the point-to-point calls performed the ping, then the pong after the ping was complete. RMA just gives an easy way to turn the ping-pong into a kind of poing operation where both are taking place simultaneously. We could have done the same thing with non-blocking point-to-point calls; however, the latency of the additional handshaking may have been enough to prevent two-way saturation of the bandwidth of the IB interconnect.
If you have further interest, you can check out pscw_pp.c, a similar poing implementation using post-start-complete-wait. Note the specification of target_rank in creating the group. This is important so that MPI_Win_wait knows from whom to expect an MPI_Win_complete.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)