Standard Send
The fourth communication mode, standard send, is actually the hardest to define. Its functionality is left open to the implementer in the MPI-1 and -2 specifications. The prior MPI communication modes are all defined explicitly, so the developer knows exactly what behavior to expect, regardless of the implementation or the computational platform being used. Standard send, however, is intended to take advantage of specific optimizations that may be available via system enhancements.
In practice, one finds that standard-mode communications follow a similar pattern in most MPI implementations. The strategy is to treat large and small messages differently. As we have seen, message buffering helps to reduce synchronization overhead, but it comes at a cost in memory. If messages are large, the penalty of putting extra copies in a buffer may be excessive and may even cause the program to crash. Still, buffering may turn out to be beneficial for small messages.
A typical standard send tries to strike a balance. For large messages (greater than some threshold), the standard send follows the rendezvous protocol, equivalent to synchronous mode. This protocol is safest and uses the least memory. For small messages, the standard send follows instead what is called the eager protocol. This protocol is like buffered mode, but the buffering is all done on the receiving side rather than the sending side, as shown below:
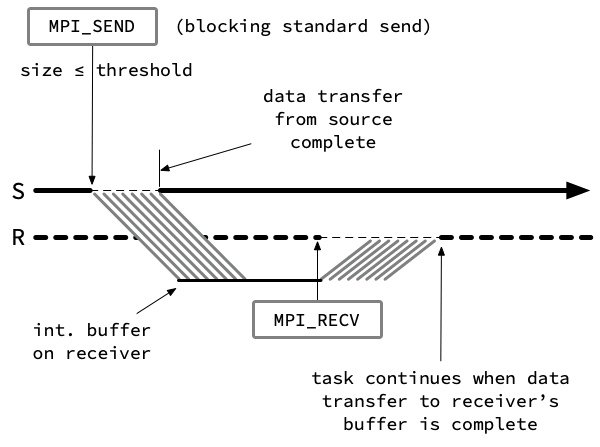
The precise threshold at which the standard send switches from the eager protocol to the rendezvous protocol is usually customizable through an environment variable. Different MPI implementations will have different names for this variable. But in any implementation, the default value of this "eager threshold" or "eager limit" should be fine for most purposes.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)