Asynchronous Offloading with Nowait
By default, when the host encounters a target region, it blocks and waits for the target region to finish before continuing to the next line of code. This may be undesirable if you intend to use multiple devices. After all, how can you distribute more chunks of work to other devices if you're stuck behind the first one? OpenMP provides asynchronous compute offloading via the nowait clause on the target directive, which launches the target region as an asynchronous task so the host can continue without waiting. The host can launch multiple asynchronous tasks on a single device or multiple devices. A synchronization point is needed later to ensure the device's work has completed before using its results. This could be an explicit taskwait directive, or an implicit barrier such as the one at the end of a parallel region.
This concept of using nowait to launch multiple tasks also works on a single device. If the host starts a parallel region with multiple threads, and if each host thread launches its own target nowait region, then each target task is assigned to a separate CUDA stream on the device. In this way, the tasks can be run in parallel, provided that the number of teams and threads for any one task does not completely fill the device.
In the example below, concurrent tasks are offloaded asynchronously onto a single device using the nowait clause. The accompanying trace visualization, which was generated by NVIDIA's Nsight Systems tool, shows that at any given moment, several of the tasks do indeed run in parallel on different streams. This is possible because we have defined the number of teams and threads for each task to be small enough so that parallel execution can take place. (Note that this example is somewhat artificial: it is likely that the loop would run fastest on a single stream. Furthermore, the example is prone to error, since indices of the subarrays and the loops must match exactly within each task.)
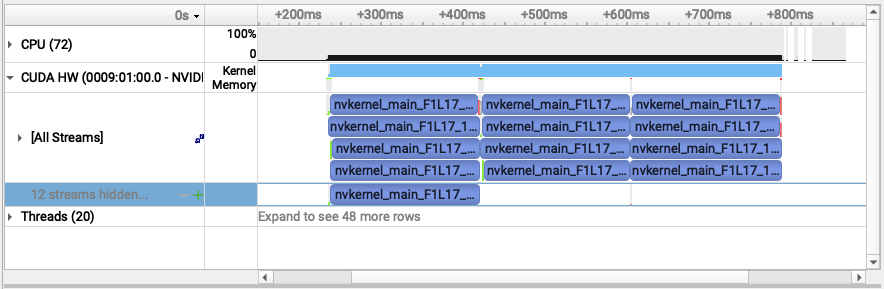
nowait_streams showing kernels running in parallel on separate CUDA streams.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)