Where to Use OpenMP
OpenMP was conceived as an API for expressing shared-memory parallelism. It is, therefore, primarily useful for applications that run on a single node of a large multicore machine. In this situation, there are several possible parallelization strategies:
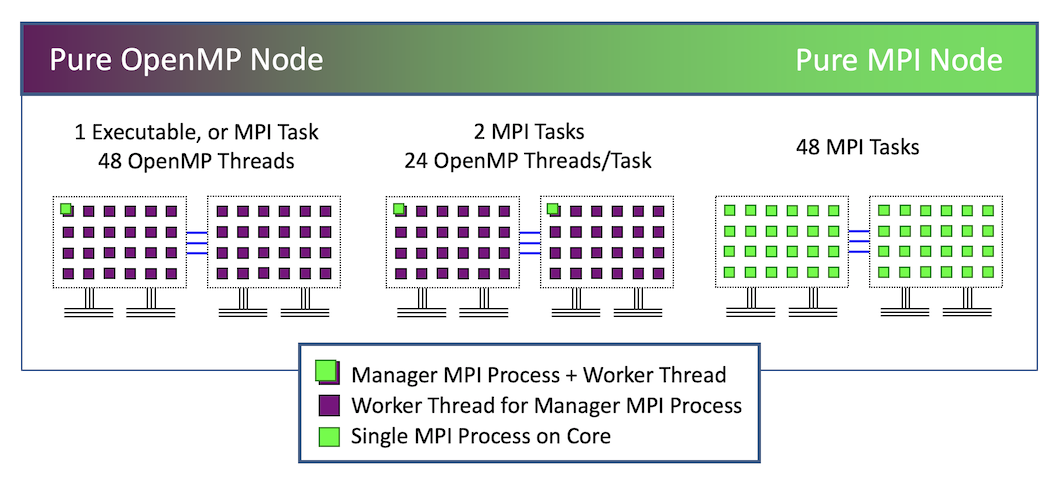
- A single executable with a unified virtual memory that uses OpenMP for parallelism.
- Multiple executables, each have their own virtual memory, communicate using MPI.
- A combination of these approaches, called hybrid programming, which is discussed in the Hybrid Programming roadmap. In hybrid programming, OpenMP is used for the portions of a multinode applications that are performed on a single node.
Assuming that you intend to use OpenMP in your application, in one of the above scenarios, where should you insert the directives to begin turning your serial code into parallel code? Ideally, this has been part of your plan from the beginning, and your code was designed with parallelization in mind. But if not, it is critical to have an understanding of where your application spends its time when working on a typical problem. Using profiling to determine the "hotspots" where the most time is spent is an important step in the process when developing parallel applications. In some cases, there is a single loop buried far inside the program where more than 95% of the time is spent. If that is your situation, then it's that loop that you should consider putting into a parallel construct, if it is eligible for OpenMP parallelization.
Identifying Parallelizable Code Sections
What makes a code section eligible for OpenMP parallelization? In order for loops or program sections to be divided up and computed concurrently in separate threads, there must be few or no data dependencies between them.
- If there are no data dependencies, you need only be concerned about scheduling the distribution of work over an appropriate number of threads. OpenMP can help you distribute this kind of work evenly. For example, a common application type involves doing a large number of independent calculations that have execution times which vary over a wide range from milliseconds to hours. Using the dynamic scheduling options available in OpenMP, the main loop over all of the calculations can be efficiently parallelized.
-
If there are limited data dependencies, OpenMP can still be useful, depending on what
kind of dependencies they are.
- For updates to global variables, you can use OpenMP lock functions or critical or atomic constructs to assure that the updates are done as uninterruptible transactions by each thread in turn.
- For reduction operations, such as finding the maximum of a quantity across all threads, you can add a reduction clause to your OpenMP construct, which allows such operations to be computed as a efficiently as possible.
- If there is an unavoidable loop-carried dependency, where each iteration of the loop depends on the result of the previous iteration, that loop is not a good candidate for OpenMP parallelization.
In the case of a loop-carried dependency, one possibility is to look for a larger loop in the program in which the problematic loop is nested. This may involve enclosing a much larger amount of your computation inside OpenMP parallel constructs, with the attendant problems of maintaining appropriate data integrity for more variables. But the improved concurrency, and hence speedup, should be worth the effort.
Another possibility is to see if smaller loops can be parallelized, inside the loop with the dependency. One common HPC application involves computing time series for a problem. There are generally many dependencies between the values of variables at each successive step and the values they had at the preceding step, so it is impractical to consider using OpenMP to compute multiple steps concurrently. However, the work involved in calculating values for the next step generally involves only variables from steps that have already been calculated, so that work can be parallelized. It is important to be aware of what the needs are for your particular case.
Other considerations arise from an understanding of parallel programming concepts, which are introduced in the Parallel Programming Concepts roadmap. Because the overhead of OpenMP is much lower than for MPI, it is practical to use OpenMP to parallelize inner loops which would be impractical to parallelize with MPI. On the other hand, Amdahl's Law says that you get more speedup if the fraction of your code that is parallelized is higher, so it is best to parallelize the outermost loop whose iterations are independent of one another and whose calculations can be done on a single node. If the best loop for parallelization is so big that more than one node is needed, then you can probably parallelize it using hybrid programming.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)