Collective I/O
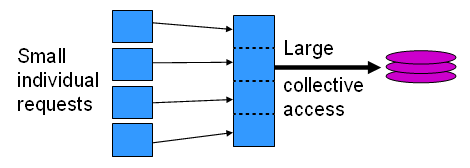
A critical optimization in parallel I/O is to take advantage of collective operations that can read from, and write to, the parallel file system. Why? There are a number of advantages:
- Allows file system to have "big picture" of overall data movement
- Framework for two-phase I/O, in which communication precedes I/O
- Preliminary communication can use MPI machinery to aggregate data
- Basic idea: build large blocks so reads/writes will be more efficient
Collective routines typically have names like MPI_File_read_all, MPI_File_read_at_all, etc. The _all suffix indicates that all ranks will be calling this function together, based on the communicator that was passed to MPI_File_open (i.e., all processes in the corresponding group). Each rank needs to provide nothing beyond its own access information; therefore, the argument list is the same as for the non-collective functions.
Collective I/O operations work with shared pointers, too, but one encounters a wrinkle in the nomenclature. The general rule is to replace _shared with _ordered in the name of the routine. Thus, the collective equivalent of MPI_File_read_shared is MPI_File_read_ordered. For both the _shared and _ordered routines, the implicitly-maintained shared file pointer will be used to determine offsets within the file.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)