Setting up Checkpoints
Training deep learning models can take a lot of computational power. Additionally, you may not create an optimally performing model at the end of the training process. For example, you may not initially select a sufficient number of epochs, have an underfit model, and need to resume your model training. Conversely, you could select too many epochs and have a model that has overfit your data, as in the following figure.
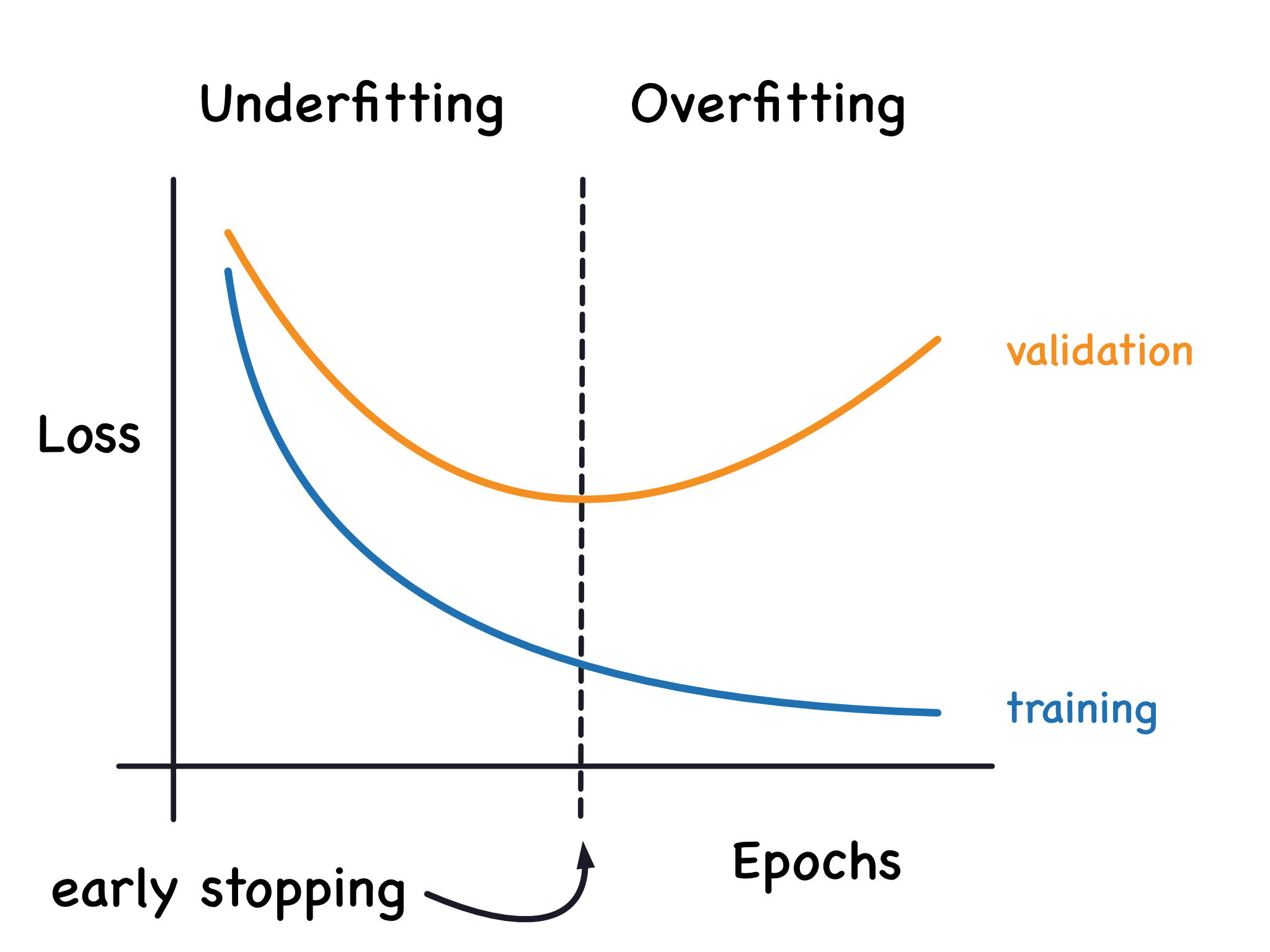
In either scenario, having a mechanism in place to save the models produced throughout the training process which results in high validation accuracy will help to ensure that you will not lose information gained throughout the training process. Throughout the rest of this notebook we will implement a process where we save our best performing model we have produced so far.
To implement this in our pipeline, first implement a function called load_checkpoint which will load a saved version of our model using torch.load.
Then we create a directory, if it does not already exist, to store our model and define a file name intended to save our best model.
As we may be resuming the training process with this code, first check to see if a previously produced best model exists and load that model’s performance (accuracy) and the model itself.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)