Training the Neural Network
Define Loss Function and Optimizer
Now that we have our dataloaders set up and a model architecture built, we are ready to train our model. To train the model, we need to set up a loss function and an optimizer to optimize that loss function. In the lab notebook, we instantiate the Cross-Entropy loss function and the Adam optimizer as was done in part 1.
There are two modifications made in the code that can lead to improved performance:
Label smoothing
Typically when performing classification we “one hot encode” the label we are trying to predict into a numerical representation that is typically integers. For example, if we are predicting cats versus dogs in images, cats could represent 0 and dogs would be represented by 1. The most helpful classifiers predict the probabilities of an outcome. That is, the model predicting 0.6 in the example above would mean there is a 60% chance that the image is a dog.
Label smoothing is a regularization technique that introduces some noise into the labels in our training data. In label smoothing, we alter the numerical representations of our data to decrease the confidence that an existing image is of a particular class in our training set. A parameter called label_smoothing, or \(\alpha\), controls how much we decrease the confidence an image is of a particular class via the following equation:
where nc is the number of classes being predicted in your classifier. Using the cat and dog classifier as an example and assuming we use a label_smoothing=0.1 we find the following new numerical representations of our labels.
Reduced learning rate on plateau
When optimizing neural networks, learning rates play a large role in the performance obtained of your model during training. Often when training a deep learning model with a fixed learning rate, performance plateaus at a particular level. It is often advantageous to lower the learning rate at this point and see if any additional performance can be gained. This technique was used in the original ResNet paper and those results are highlighted below:
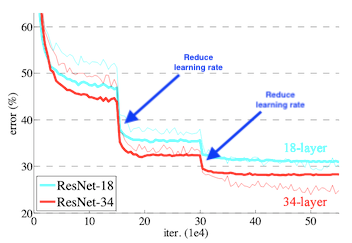
There is a tool in PyTorch – torch.optim.lr_scheduler.ReduceLROnPlateau – which automatically detects when a performance plateau has occurred and lowers the learning rate by the parameter factor after the plateau has been detected.
Below we instantiate the optimizer, loss functions, and learning rate scheduler with techniques highlighted above.
[1] Hammel. URL: https://www.bdhammel.com/learning-rates/
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)