Review: PyTorch DDP
In the previous notebook, we have done distributed training with PyTorch DistributedDataParallel (DDP) on multiple GPUs residing on one node. DDP can also run across multiple nodes.
DDP uses collective communications in the torch.distributed package to synchronize gradients and buffers. More specifically, DDP registers an autograd hook for each parameter given by model.parameters() and the hook will fire when the corresponding gradient is computed in the backward pass. Then DDP uses that signal to trigger gradient synchronization across processes.
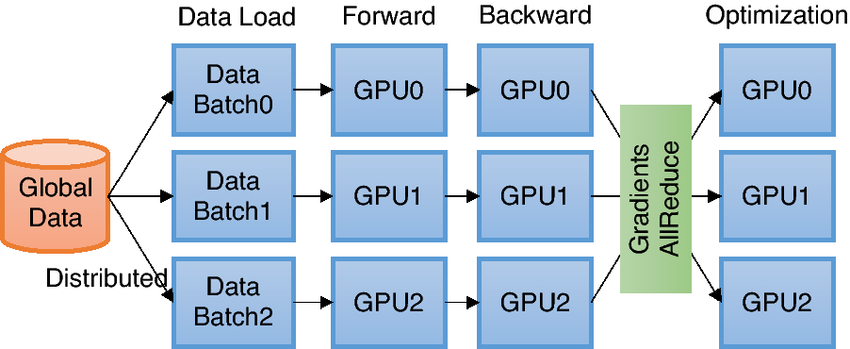
Image source: [1]
The basic idea behind DDP is the following - we create processes that replicate a job multiple times. PyTorch DDP uses torch.distributed.init_process_group method to set up a process group, and distributes data amongst processes with DistributedSampler. It also prepares model implementation with DDP wrapper.
We are introduced to some environment variables that glue the training environment together: WORLD_SIZE, GLOBAL_RANK and LOCAL_RANK. They are fancy names for “total number of GPUs in your job”, “the ID for the GPU in your cluster” and “the local ID for the GPU in a node”.
[1] Choi, Jong Youl & Zhang, Pei & Mehta, Kshitij & Blanchard, Andrew & Lupo Pasini, Massimiliano. (2022). Scalable training of graph convolutional neural networks for fast and accurate predictions of HOMO-LUMO gap in molecules. Journal of Cheminformatics. 14. 10.1186/s13321-022-00652-1.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)