INSERT
INSERTing data
Getting data in a database is done with the INSERT command. RDBMSs generally have their own tools for bulk inserts, including reading data from a file, but adding a row's worth of data to a table is done with INSERT. The INSERT syntax is fairly simple:
Note that an attempt to add data which disobeys a constraint will be rejected. This might be a foreign key value which isn't present in referenced column in the primary key table, for example, or data with the wrong datatype or a NULL value in a non-NULLABLE column, etc. You can omit the list of columns names if you are providing a value for each column and give them in the right column order, but in general it is better not to rely on this; if you are not providing all of the values (because a column is an autogenerated IDENTITY column or because a column accepts NULLs or has a default value), you must list all of the column names.
As an example, here is how we might INSERT a new row into this measurements table:
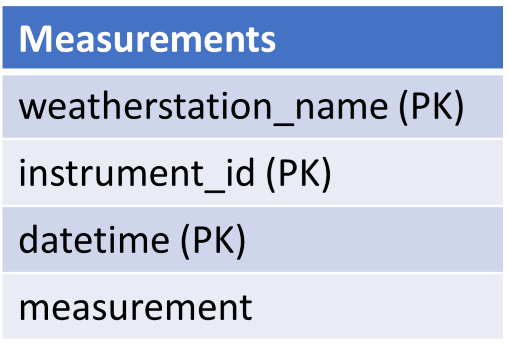
This will insert all of the given values or none at all. Note that the weatherstation_name and instrument_id are also foreign keys to the Weatherstations and Instruments tables, respectively, so the values entered must be present in the corresponding columns in those tables. Getting the necessary values may require precursor queries if they are surrogate keys with no semantic content (as with instrument_id).
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)