Hybrid Configuration Options
Some possible MPI + thread configurations
-
Treat each node as a Symmetric MultiProcessor (SMP)
- launch a single MPI process per node
- create parallel threads sharing full-node memory
- typically want 48 threads/node on Stampede3's Xeon Skylake nodes
-
Treat each socket (processor) as an SMP
- launch one MPI process on each socket
- create parallel threads sharing same-socket memory
- typically want 24 threads/socket on Stampede3
-
No SMP, ignore shared memory (pure MPI)
- assign an MPI process to each core
- in a manager/worker paradigm, one process per node may be manager
- not really hybrid, may at least make a distinction between nodes
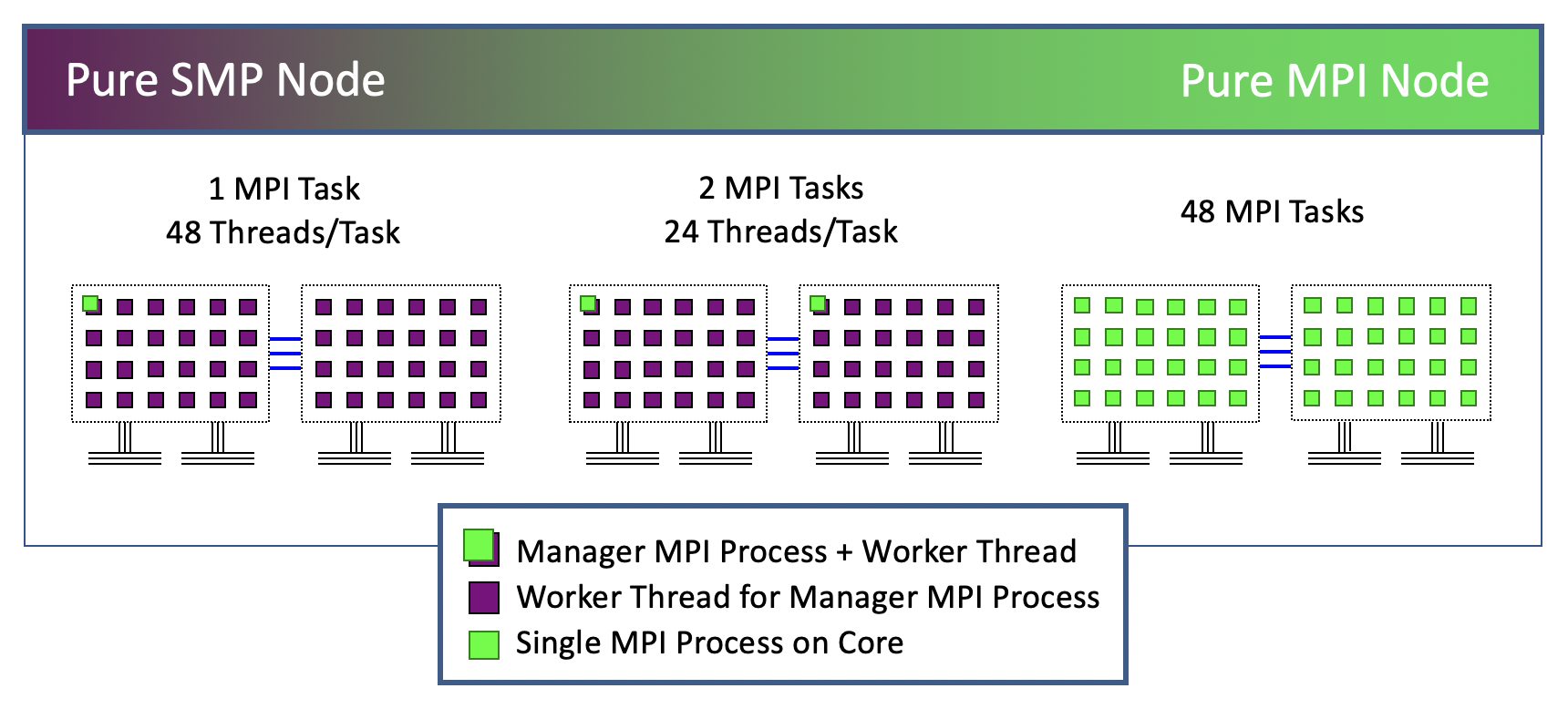
In the node-as-SMP configuration (shown on the left in the figure), all the cores on a node are used by OpenMP threads with access to the same virtual memory. In the pure MPI strategy (right), each core on the node runs an independent task with independent virtual memory.
In the socket-as-SMP configuration (middle), the cores are grouped by socket, with one MPI task and several OpenMP threads per group. Virtual memory is shared within each thread group. Optimally, the virtual addresses are mapped to the physical memory of the socket where the thread group is running. This tells us that on NUMA architectures, we would like to have some control over the placement of threads and processes. Therefore...
-
To optimize hybrid configurations like these, we must be able to:
- assign to each process/thread an affinity for some set of cores
- make sure the allocation of memory is appropriately matched
Fortunately, various methods are available for making such assignments.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)