SQL Databases
Many useful and important datasets are stored in relational databases that support the Structured Query Language (SQL). Relational databases (DBs) are essentially collections of tables, similar to dataframes or spreadsheets, that contain relationships among tables in the form of shared keys (identifiers of different data items). The linkage between tables through these shared keys enables one to build up more complex data structures beyond the two dimensions defined by a single table. The topic of relational databases and SQL is far beyond the scope of this tutorial, and we refer readers to our companion material on Relational Databases for more information. In this tutorial, we intend mainly to provide some guidance about how to connect to SQL databases in Python and to convert some of the results of SQL queries to Python data structures such as Pandas DataFrames for further processing.
There are many different tools that manage relational databases, termed — appropriately enough — Relational Database Management Systems (RDBMS). These include large applications that often reside on remote machines dedicated to serving up access to a database — such as Oracle, MySQL, and Microsoft SQL Server — as well as more lightweight RDBMSs that you can install and run on your own desktop/laptop such as SQLite and SmallSQL. Each presents somewhat different syntax for connecting to them from an external environment such as Python, and a variety of Python libraries have been built to support such interactions. Most if not all of these systems involve creating an object within Python that represents a connection to an RDBMS engine, which can then be acted upon to read/write data from/to the database. The library SQLAlchemy is a Python SQL Toolkit and Object Relational Mapper that provides a variety of operations for working with SQL databases, and aims to provide — among many other things — a common interface for connecting to a variety of RDBMS. In addition, the Pandas library discussed previously is capable of reading and writing data not just from flat files and spreadsheets, but also from a SQLAlchemy connection object. We will demonstrate a small bit of that functionality here.
The key piece that we will use from SQLAlchemy is the create_engine function, which creates a database engine object that we can read from or write to using SQL statements. For the most part, this function can be called with a single argument — a connection string — which describes how to connect to the RDBMS and database of interest. Each RDBMS has its own syntax for configuring such connections, and getting the correct connection string can sometimes take some experimentation, but the SQLAlchemy Engine Configuration Page provides many examples. In this tutorial, we are mostly interested in creating, and then subsequently reading from, a SQLite database on our local disk. In particular, since the BaseballDatabank data consists of multiple interrelated tables, it provides a useful application example for this functionality.
The interoperation of SQLAlchemy and Pandas
The following statement opens a SQLAlchemy connection to a SQLite database stored in a file named mydb.sqlite:
Recall that our baseball data was stored in a Python dictionary holding 27 dataframes, keyed on their names. Using the to_sql defined on Pandas dataframes, we can write each one of these 27 tables to a sqlite database. The following function creates an engine, loops over each of the dataframes stored in the dictionary dfs and writes it to the DB, and then disposes the engine at the end:
And the following code will call that function to write out all the dataframes to a DB named bbdb.sqlite:
With all the data in a SQLite database, we can now connect to it and issue SQL queries to extract information of interest. Fortunately, just as pandas provides a convenient function for writing dataframes to a DB, it also provides a useful function to excecute a SQL query and return the results stored in a dataframe. We will not cover the syntax of SQL queries here, but provide a specific example instead: code to select — from the batting table in the DB engine — the top 10 most hits (H) produced by a hitter in a single season:
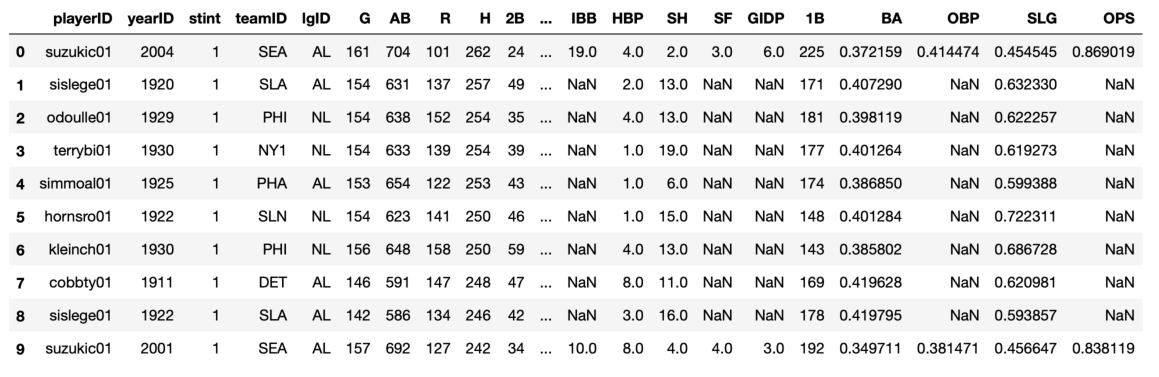
If you're a baseball fan, maybe you already knew that Ichiro Suzuki (playerID suzukic01) currently holds the record for most hits in a season (262 hits in 2004), having topped George Sisler's long-standing record (257 hits in 1920). But if you're curious about the names attached to the somewhat obscure playerIDs stored in the batting table, you could issue a more complicated SQL query using a table join to extract the players names from the people table (using Python's triple quotes to create a multiline string to accommodate the long query):
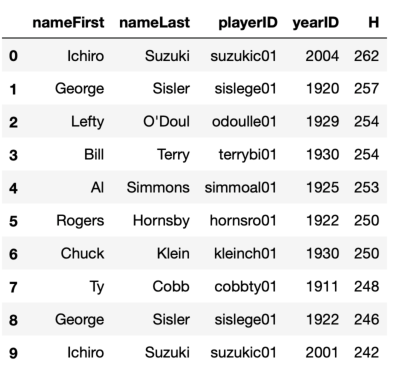
What's the point of all this back-and-forth between pandas and SQL?
This example might seem a bit contrived. To begin with, the data were in a standard csv format, which we were able to read conveniently into pandas dataframes in order to leverage all the processing power that pandas provides. But then we wrote all those dataframes out to a SQLite database, just so that we could read them back into pandas, which requires knowing how to craft SQL queries. While admittedly a somewhat atypical workflow, here are at least a few different reasons why you might find it handy to use some of this sort of functionality in your own code:
- Maybe the data you want is already stored in a SQL DB, and you want to get it out to process further in pandas.
- Maybe you already know SQL, and would rather extract targeted pieces of information using that syntax rather than figuring out how to do something analogous in pandas. (Pandas does provide substantial functionality to Merge, Join, and Concatenate dataframes in a manner similar to the sorts of join operations provided by SQL. We encourage readers interested in more complicated data aggregations to consult that material.)
- Maybe the total extent of the data is very large, but that you only need to extract subsets of it for particular calculations. Rather than having to hold all of that data in memory (which might not even be possible), you can use SQL queries to pull out just those pieces you need to work with further.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)