Groupby Operations on Data
Aggregating data: split-apply-combine and groupby
Sometimes the data processing that we want to do involves more complicated manipulations of the raw data beyond simply adding new columns to the existing data tables, or performing aggregate operations over an entire dataset. Because a data table potentially involves a lot of internal structure associated with the values of entries in the table, we sometimes want to aggregate over subsets of the data to compute some properties about those subsets.
Groupby operations represent an extremely powerful set of capabilities in pandas for manipulating dataframes, providing support for a general class of so-called "split-apply-combine" operations. This means, for example, that we can:
- split a dataframe into groups based on identity of a specified key or some other criterion
- apply an aggregating function across each of the subgroups
- combine the aggregated information back in a single dataframe
For example, each row in the batting dataframe contains information about a single player in a single year. What if we wanted to know the totals of all of those statistics, on a year-by-year basis. We can create a new dataframe very simply by grouping by the 'yearID' and then summing each of those year-by-year groups:
- split the dataframe into a group for each year
- apply the summation (sum) aggregating function within each group
- combine the year-by-year summed data back in a single dataframe
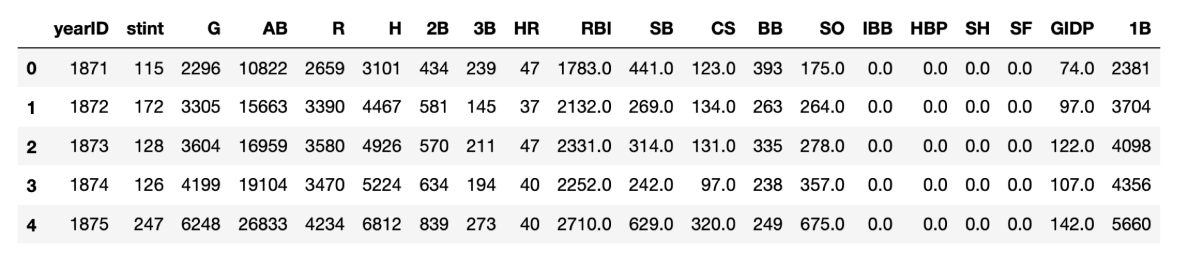
Alternatively, instead of grouping by year to get league-wide statistics for each year, we could group by player (playerID) to get career batting statistics for each player:
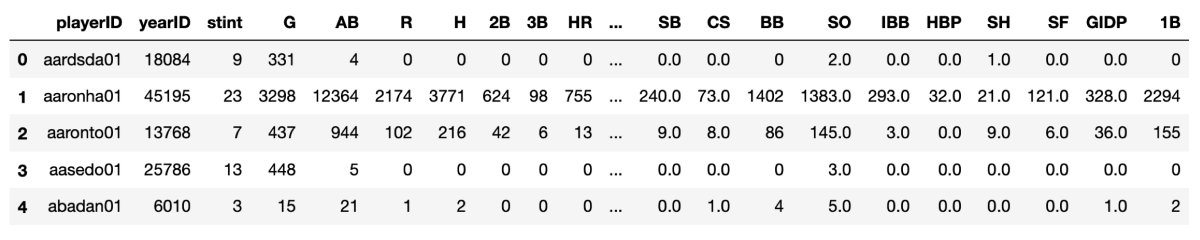
As a technical aside, in both examples above, we chained several operations together in one expression, concluding each with the method reset_index(). What is that operation for? Recall that the index of a dataframe is the group of labels for each row. In the raw dataframes that we created when we read in the csv files, the index was simply an incrementing set of integers over each of the rows. When we execute a groupby operation such as those above, a new dataframe is returned, and the index of that dataframe is the set of labels that we grouped on, e.g., the yearID's in the first example and the playerID's in the second example. Sometimes it is useful to keep the groupby key as the index, but sometimes you might want to put the key back in as a regular column, and use incrementing integers as an index instead. That's what the reset_index() method does. Feel free to experiment with this in the notebook, for example, removing the call to reset_index so that you can inspect the dataframe that is returned without that call.
Note that the "Slash Line" statistics that we added to the batting dataframe in the previous exercise have not been correctly aggregated here in the pl_bat dataframe. That is because those statistics are all averages of year-by-year counts. A player's career batting average, however, is not the sum of his year-by-year batting averages (or even the mean of those averages). Instead, career-wide Slash Line statistics would need to be recomputed based on the aggregate counts in the pl_bat dataframe, as in the code below. Thus while a dataframe is easily extensible, we also need to keep in mind whether adding new types of data changes the semantics of the table.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)