The Shape of Speedup
What factors determine the shape of the speedup curve as a function of N, the number of workers? Let's look again at our performance model that includes communication costs:
\[total~time = {workload \over N} + serial~time + (k_0 \times N^a) \times latency + {(k_1 \times N^b) \over bandwidth}\]The first thing to appreciate is that the second and third terms depend on the latency and bandwidth of the hardware in the cluster! Thus, the optimum core count may change drastically if the code is moved to a different machine where the latency is, say, almost the same but the bandwidth is double.
Otherwise, our result depends strongly on the communication pattern of the application. If the tasks send lots and lots of small messages, the latency term is weightier (through k0). If the tasks send a few large messages, the bandwidth portion is more important (through k1).
Now, what values should we assume for the exponents a and b? You might think they would be close to 1, as more workers means more messages. But in an HPC system like Frontera, the effective size of the network also grows like N, so more workers mean more interconnections. Perhaps the whole set of messages can even travel simultaneously, all in parallel! In that case, both a and b could be close to 0. But everything depends on the details of the parallel algorithm. If each worker must send a message to all the other workers (all-to-all communication), the number and total size of messages might well be proportional to N2, implying an a and b equal to or greater than 1 (even assuming the dense parallel network described above).
An example
Imagine a parallel code that simulates heat flow in a flat metal plate. The code splits the plate into plaquettes; every plaquette is assigned to a different task. Each task needs to communicate only with its nearest neighbors. As N increases, the number of messages per worker is unchanged, while the message size per worker actually decreases as N-1/2. Assuming there is an excellent network that allows all messages to travel in parallel unimpeded, we find that a = 0 and b = -1/2. Therefore, we see that the latency cost will come to dominate at large N. It happens that this cost mimics the serial time from Amdahl's Law, so we can hope that the blue curve below applies and not the purple one (unless the network is less capable than assumed). It should be clear that for other types of applications, the a and b exponents might be smaller or larger.
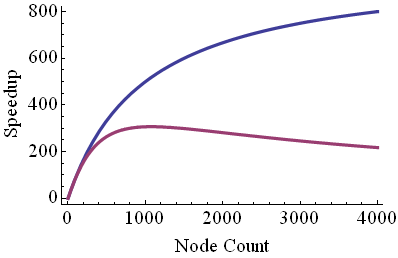
To see the different regimes of scaling in a model of this type, we hope that the number of cores in the test cluster is large enough to produce large-N behavior. If it is, then doing a linear fit to a log-log plot, for points past the "bend", is almost always the way to go. If not, it may be possible to fit the data using all the terms above. From such a detailed fit, we can infer the power law for the term that dominates at large N. Armed with this fit, a simple Excel spreadsheet will let us predict how well the code will run on a given cluster. It may not be a great estimate, but it may be good enough to tell you the number of nodes on which a code will be sufficiently efficient.
Latency hiding
In the above example, we see that latency costs eventually dominate for large N. But that trend won't hold for calculations that can do latency hiding. In this technique, a process sends data items to neighboring processes before they are needed, so that computation and communication overlap. One can imagine a highly-tuned synthetic benchmark like HP Linpack, for instance, taking advantage of this type of message prefetching. At present, it is a hardware-dependent strategy that should grow in importance as direct memory access (DMA) by remote processes becomes more prevalent. DMA is more readily achieved for intra-node communication, as opposed to communication over a network.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)