Cache and Memory
Although profiling is a valid technique for finding areas in code that may be problematic in terms of vector efficiency, the programmer should also have an idea of the memory access patterns that will lend themselves to good or bad vector performance. Such knowledge is useful when it comes to fixing the problems that are identified by the profiler.
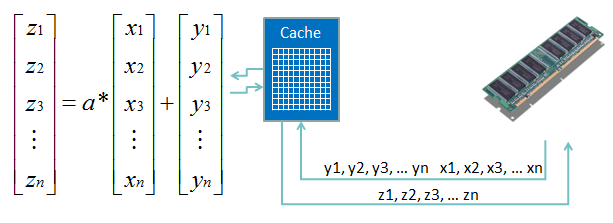
As implied in the above figure, moving data into and out of vector registers involves several levels of the memory hierarchy. The movement of data from RAM to cache to vector registers (and back) is necessary, but it can be expensive in terms of precious CPU cycles wasted on memory latency.
Prefetching is one common strategy to avoid memory latency costs. Prefetch instructions are introduced into codes automatically by the compiler, or explicitly by the programmer through compiler directives, or through calls to certain instrinsic functions. However, today's Intel processors all feature hardware prefetching; this makes explicit prefetching less necessary than it used to be.
Since access to main memory is very slow compared to cache or registers, one should focus on main-memory access patterns that lead to superior performance. Our watchwords are: infrequent, predictable, sequential, and aligned. The best performing code makes maximal reuse of data in cache and registers, so there is infrequent loading of data from memory. The reason for predictable access is simple: it makes hardware prefetching work better! Sequential and aligned access come into play due to the way memory is organized in hardware—as we will now explain.
Data travel back and forth between memory levels in units of a cache line. In KNL, SKX, and ICX this unit is 64 bytes (8 doubles), which is the same as the AVX-512 vector width (no coincidence, surely!). Thus, cache and memory accesses in these processors are most efficient when memory accesses are stride 1 and the data can be retrieved in multiples of 64 bytes. Data aligned on these memory boundaries move readily from registers to cache to memory in single operations. By contrast, misaligned data may require multiple memory transfers in order to deal with values that straddle alignment boundaries. (For sequential data, such misalignment typically occurs only at the beginning and end of a loop, and the compiler can often cope with it.)
Compilers are usually very good at automatically assuring that variables and arrays are properly aligned for optimal performance on a given platform. To make
absolutely sure of this, you can add the alignas(64) keyword or __attribute__((aligned(64))) to C/C++ static arrays, and
allocate dynamic arrays using memalign(64, size) or aligned_alloc(64, size). With Fortran, the easiest way to enforce correct
alignment of static and dynamic arrays is through a compiler option such as ifort -align array64byte.
In the case of arguments to functions or subroutines, though, the compiler may not know for certain that all the variables given as arguments will be suitably
aligned. This can cause it to revert to cautious (and expensive) checks. Fortunately, there are ways of instructing the compiler to assume that all data are
aligned. Modern C/C++ offers the __assume_aligned(a, 64) clause as a language feature for this purpose. Alternatively, all the variables
referenced in a loop can be covered with a pragma or compiler directive.
OpenMP provides portable syntax for doing this through its SIMD instructions, while #pragma vector aligned works with the Intel C/C++ compiler.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)