Turbo Boost
The latest Intel processors adjust their clock frequency according to workload. This gives yet another reason why doubling the vector width will not necessarily double the performance: doing arithmetic with wider vectors consumes more energy and produces more heat. The processor will try to compensate by throttling down the clock frequency, especially if most or all of its cores are in use.
The first plot below presents some of the data that Intel has published for the 24-core Skylake Platinum 8160.1 It shows that for a given number of occupied cores, the actual frequency experienced by each core will will fall between the Turbo Boost rate (dashed line) and the base rate (solid line), according to the instruction set of the application that happens to be running on it (color). The plot does not tell you the exact core count at which a given multithreaded application will start to see a decrease in frequency, because that depends on the code itself, which may or may not keep the cores very busy.
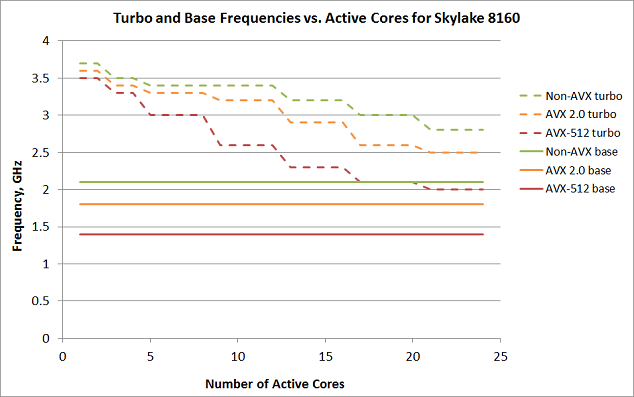
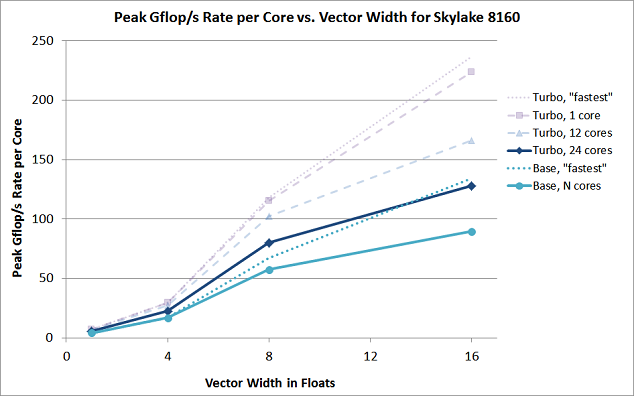
The second plot just gives a different view into the same data. It shows how the Gflop/s rate per core on Skylake can potentially climb as the vector width increases. Each curve traces the rates for successively larger vector widths, for a fixed number of cores, at either the turbo or base frequency. This relationship is not linear, because in general the cores must reduce their frequency in order to handle the wider vector instructions. (Note too that cores may not be able to sustain their Turbo Boost frequency; this would tend to move the actual performance closer to the base frequency.) The figure also takes into account the availability of the fused multiply-add (FMA), which is present in the AVX2 and AVX-512 instruction sets, but absent from scalar and SSE instructions. An FMA vector unit effectively doubles the rates for 256- and 512-bit vectors (at least in theory), which helps to compensate for the frequency reduction at those vector sizes.
Clearly, to estimate the fully vectorized performance of a code on all cores of an Intel processor, it would be unwise to extrapolate from naive tests of unvectorized code on a single core. The precise behavior of the hardware will depend on the vector instruction set(s) that are found in the compiled application, the density of these instructions, and the speed at which they are issued by the code as it runs on one or more cores.
One consequence for Skylake, in particular, is that compiling with the -xCORE-AVX2 flag (for 256-bit vectors) may, at
times, be preferable to compiling with the -xCORE-AVX512 flag (for 512-bit vectors). Likewise, as mentioned previously,
when the -xCORE-AVX512 flag is set, the option -qopt-zmm-usage=high may actually reduce performance. It can be
worthwhile to compile and test your code with various compiler flags, to see what combination performs best.
1. Intel Xeon Processor Scalable Family Specification Update , Intel Corp., February 2018. ^
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)