Profiling
As mentioned in the prior discussion of Amdahl's Law, the overall speedup due to vectorization is largely determined by the percentage of a program that is vectorized. But many factors influence performance, and it is generally impossible to deduce all the reasons for a speedup that seems unexpectedly low, simply by looking at code. Cache misses, memory accesses, branch mispredictions, etc., tend to disrupt a program's execution and can negatively affect an application's effective use of vector resources.
Although vector reports are a useful tool for determining whether a compiler is properly vectorizing code, and where it is trying to vectorize, the reports are not as useful for determining how the application will perform in practice. Evaluating application performance with regard to vectorization is best achieved by targeted profiling. The Profiling section of the Cornell Virtual Workshop topic on Profiling and Debugging describes common tools and techniques for finding out where the code is spending its time in various code sections or functions.
Let's highlight just a couple of the methods in Profiling. First, you can measure the time taken by selected routines or loops by inserting calls
to a standard timing function such as gettimeofday() within the application itself. This is helpful for determining whether a particular loop is getting a decent amount of
speedup, for instance. However, you should be aware that the intrinsic resolution of such timers, and the overhead of the function calls themselves, may lead to measurement inaccuracies.
Second, gprof gives you a rough-and-ready way to profile your code so you can spot the time-consuming functions. This might tell you which parts of your code would benefit from
greater vectorization. In both cases, you have the option of recompiling your code with -no-vec and comparing results to see where your vector performance gains are less than
expected.
Intel's profiling tools are highly accurate in detecting specific areas within applications that, while vectorized, might not offer optimal performance on Intel processors. Problems such as non-sequential access and poor reuse of data within caches can lead to inefficient execution by introducing pauses and delays due to cache misses, memory transfers, etc. These issues are hard to localize without tools to analyze runtime performance in detail. Intel's tools turn out to be quite good for this, so we will discuss them in depth.
Intel Advisor
Intel Advisor XE is a tool that combines two types of profiling to give greater insight into vectorized code performance. (In fact, it used be called Vectorization Advisor.) It offers detailed profiling down to the loop level to see which code sections are taking the most time. It can also run the code through an emulator to count how many times each individual instruction (vector or otherwise) is executed. When it performs the emulation, it accounts for the same branches and loop iterations that the code would follow when running on the real processor cores, so the instruction counts come out precisely the same as in a real run of the code.
By combining these two metrics, Intel Advisor produces an accurate flop/s rate for the code, either as a whole, or in its subsections. Moreover, the tool can compute the related statistic of flops/byte, also known as arithmetic intensity or AI. The latter can help identify parts of the code that are memory-bound, because any given processor can only sustain its maximum computational rate above certain AI thresholds. All these properties are neatly summarized in a roofline plot; an example of such a plot is shown below.
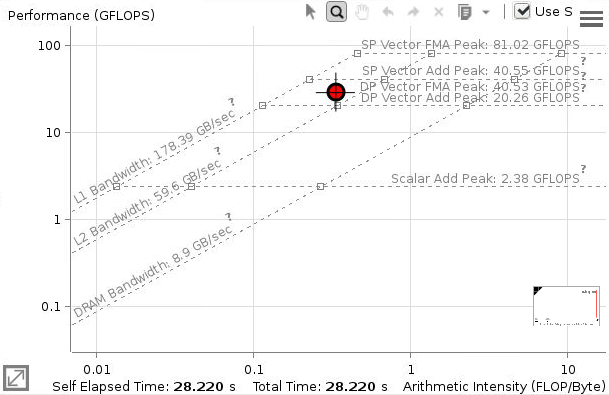
As the roofline plot illustrates, the higher the AI (x-axis), the greater the potential for reaching peak performance on one or many cores. The red dot shows how close the code's main loop got to the theoretical peak flop/s rate on a single core. The kernel of this particular loop consisted of two FMAs, two loads, and one store: (4*16 float-ops)/(3*64 load-or-store-bytes) = 0.333 flops/byte. In the GUI, hovering over the dot with the pointer would display this and other details.
It is possible to run Intel Advisor directly on TACC compute nodes. GUI mode is best, so it is recommended that you start your job via the TACC Analysis Portal, as that's the easiest way to get a VNC desktop. Here are the commands to compile a test code with a GNU compiler and launch Advisor (enter these in a fresh terminal window, otherwise you will disconnect your VNC when you quit Advisor):
Much more could be said about Advisor. For example, it can be used to view vectorization reports and pseudo-assembler output from the compiler, with handy links right into the source code. But that would be a whole topic in itself!
Intel VTune
Intel VTune Amplifier XE is a comprehensive profiling tool that has the ability to read many types of hardware performance counters in real time while a code is running. These counters record events such as cache hits/misses, branch mispredictions, and other hardware-level details that can indicate inefficient code (in its General Exploration analysis).
More than that, VTune computes ratios and combinations of the hardware counters in order to offer you a plethora of insights into application behavior. Any metrics that depart significantly from their optimal values are flagged for follow-up. With the VTune GUI, you can drill down into the exact lines of source code that may be causing the problem—and even into their assembler translations. Timelines of the activity on each thread are integrated with the counter data. Here again, zoom-and-filter actions allow you to home in on problem spots quickly.
If this sounds like a lot—it is! VTune is a complex tool, and some experience is necessary in order to take full advantage of it. But like Advisor, VTune is aided by a nice GUI that invites exploration.
An important feature of Intel processors is the ability of the hardware counters to track vector operations. When these counters are available, as they are on TACC systems, VTune lets you take a peek at them. It even computes a metric for vector efficiency based on their values. (Be aware that the count of vector operations includes loads and stores as well as floating-point computations.)
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)