Models and Modeling
The Past
Models have long been used in science as a means for encoding something about our understanding of phenomena in nature, and as a way of making predictions about as-yet-unseen circumstances, including the unfolding of the future. George Box is often quoted as having written, “All models are wrong, some are useful.” But apparently what he actually wrote was, “Remember that all models are wrong; the practical question is how wrong do they have to be to not be useful.” Models are simplified and idealized representations of a complex reality, but they can nonetheless be useful in helping to provide insight into that reality, or in making decisions about next steps to take.
There exist different broad types of modeling approaches used throughout science. Descriptive models are focused on describing patterns in data, and more specifically the relationships among a set of measured variables, without providing any information about
In the earlier history of machine learning, this "black box" quality and the associated lack of model interpretability was — for some researchers — reason enough to shy away from using such methods as part of the larger research enterprise. This was perhaps more the case for researchers who gravitated toward mechanistic models based on physical, chemical, and biological principles, where the process of understanding how specific mechanisms and interactions give rise to observed collective phenemona can be a key element of scientific insight and a gateway to making actionable model predictions. As ML models have became sufficiently powerful, however, many of those particular concerns have become muted, as many researchers have become more willing to trade off model interpretability for model performance.
The Present and Future
Tools from machine learning are increasingly used to develop predictive models of complex phenomena that might have previously been tackled via mechanistic simulation or some related form of analysis. In condensed matter physics and materials science, for example, one might be interested in designing some new material with a specified set of properties, but those properties emerge from the collective interactions of many components, such as electrons, atoms, or molecules. Trying to reverse engineer what components could be added to achieve a desired set of emergent properties has a long history in these fields, often relying on forward simulation of the interacting components based on known rules, mechanisms, or methodologies. Those forward simulations are sometimes either very computationally expensive, or inaccurate enough that they do not provide sufficient predictive power for design. Increasingly, these sorts of mechanistic models are being bypassed in favor or machine learning and/or deep learning models that are trained on sets of labeled data connecting the input components to the output properties, perhaps arising through experiments, simulation, or both.
In some cases, the development of mechanistic models of complex systems is hampered by our incomplete understanding of the processes at work in those systems. But we often have some partial information, or insights into at least some of the mechanisms underlying a complex system. Therefore, we can perhaps augment that information with other computational elements that can be learned from data, without having an underlying mechanistic or process-based specification, such as those that arise in machine learning and deep learning. This is the basic premise behind various hybrid approaches that aim to blend aspects of mechanistic models with ML/DL models. A few examples of these sorts of hybrids include Physics-informed neural networks (PINNs), Universal differential equations for scientific machine learning, and partial differential equations (PDEs) with operators learned from data. In the field of astrophysics, AI techniques have been used to augment physical models and constraints in order to reconstruct images of the 3D structure of a flare erupting around a black hole, which would have been difficult without the use of AI due to the nature of the data collected (see figure below). AI-based models for weather forecasting and climate modeling are being used to complement and compete with more traditional physics-based models that require substantial run times on large supercomputers. These are just a few examples of how hybrid approaches that blend and integrate different modeling techniques and perspectives are being used to move science forward.
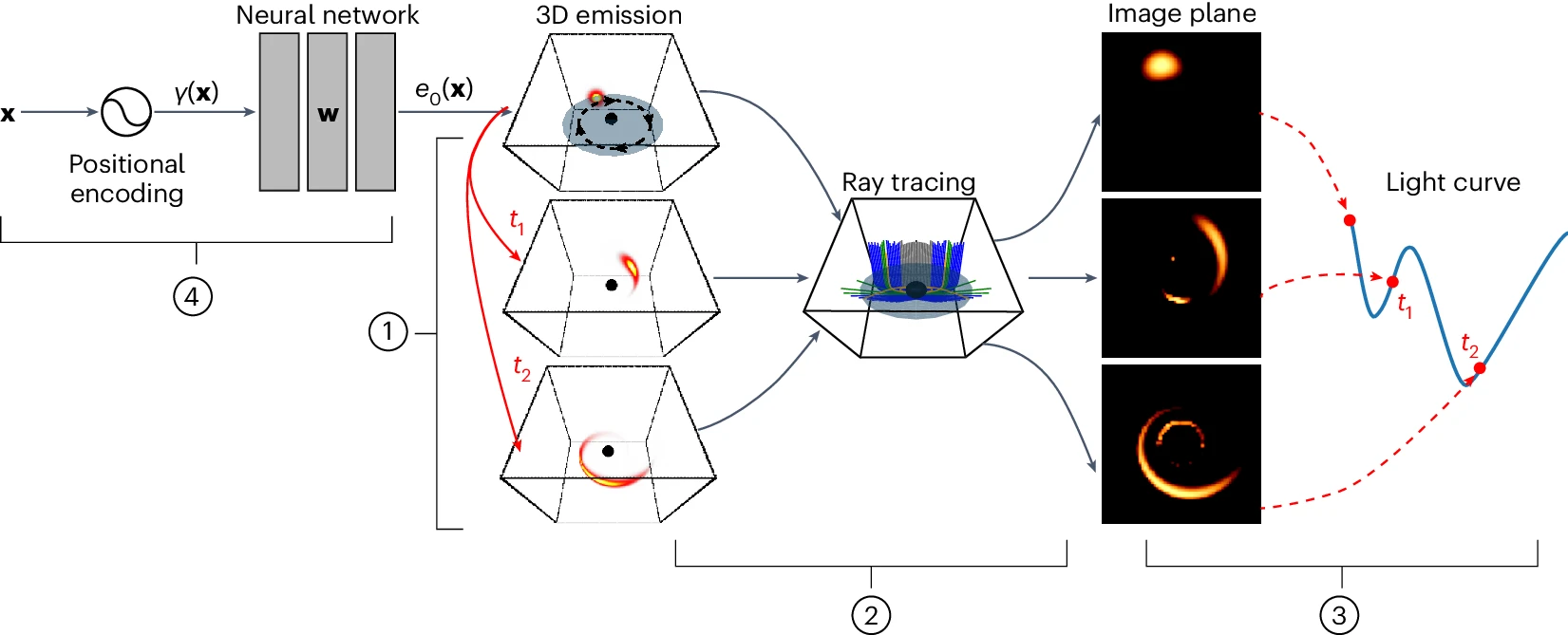
Image credit: Levis et al., https://www.nature.com/articles/s41550-024-02238-3
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)