Advanced Cache Topics
We have seen that the specific way in which you write source code can affect how well the compiler is able to translate the code into efficient machine instructions. Similarly, the way you organize your source code can affect the timing of the arrival of data at various cache levels and influence its residence time there. This in turn determines how quickly your data are available when needed. The simplest advice is still to use unit-stride accesses to fetch the data, and to reuse data as much as possible after fetching them. But there are other, more advanced techniques for managing cache space carefully for the sake of optimizing performance. We discuss just a few of them in the pages to follow.
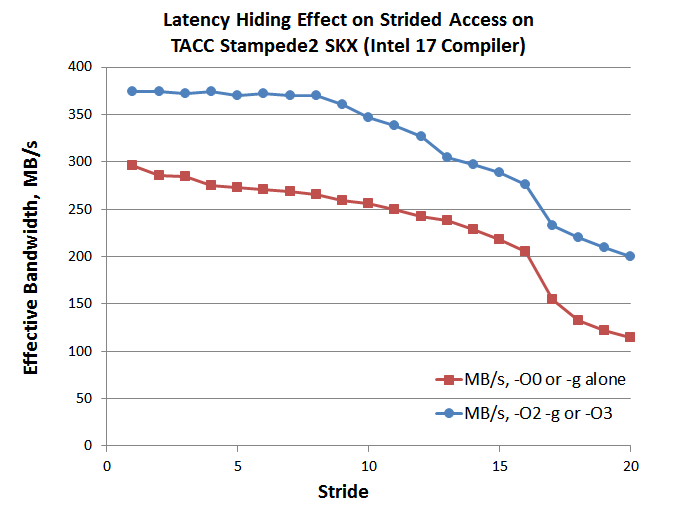
Perhaps the best-known technique is called latency hiding. This just means having the core do other necessary calculations while data are being fetched from somewhere deeper in the memory hierarchy. Sometimes this happens quite naturally, because the intended computation already involves a good amount of data reuse. The compiler can then schedule fetch operations to take advantage of these built-in delays.
Quick exercise: Download, compile, and run the code busystride.c. This code expands upon our previous example, stride.c, simply by doing more work on each item that is fetched from memory. (It converts the uniform distribution of the original random numbers to normal or Gaussian; while the numbers are being converted, it incrementally computes the standard deviation and the mean of various strided subsets of the random number array.) Due to the extra calculations being done on each data point, the code runs much more slowly overall, compared to our previous results. But because of latency hiding, the stride dependence is greatly reduced. Stride 8 runs virtually as fast as stride 1, and stride 16 runs only 25% slower.
Clearly, it would also be advantageous to bring extra data into cache before they are needed, so they can be accessed quickly once they are actually called upon. This is called prefetching, and it is often done in software. But you should be aware that in today's Intel processors, every core has hardware prefetchers that are constantly working on your behalf! Multiple, distinct prefetchers are present at the L1 and L2 levels.1 Details can be found in the latest Intel 64 and IA-32 Architectures Optimization Reference Manual: Volume 1, Chapters 3, 9, and 20.
1. For example, in Intel's circa 2011 "Sandy Bridge" processor, there are four prefetchers per core, two for L1, and two for L2. "Streamers" (one for each level) are most important for stride one accesses; they begin to issue prefetches when they detect a pattern of ascending accesses. The additional L1 prefetcher tries to anticipate regular strides of other sizes by looking for patterns in the instruction stream. Finally, the L2 "spatial prefetcher" tries to bring in two cache lines instead of just one for all L2 loads. In principle, it can make prefetching twice as effective. This information can be found in the old Intel 64 and IA-32 Architectures Optimization Reference Manual, 2.1.5.4, Data Prefetching.^
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)