Single-Core Principles
Attaining good global performance depends on more than writing a parallel program and making sure it is arranged correctly for the target parallel architecture. It also depends on making sure that one's single-CPU implementation in the program translates well into single-CPU machine code.
A typical cluster consists of multiple computers that are linked through a network. The computers correspond to the nodes in a graph of the network, so they are often just called nodes. Each node houses one or more processors consisting of some number of independent CPUs called cores. You can gain significant benefits by paying attention to behavior at the node level, and even at the core level. Performance at these levels is largely influenced by the particulars of how the algorithm is realized: how it is expressed in high-level language, and how the compiler converts the high-level program into a specific sequence of operations on data. These are the stages where "rough tuning" comes into play.
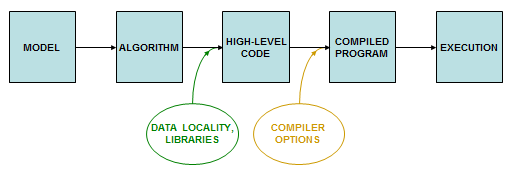
The ability to achieve good single-core performance can be broken down into three basic principles, which we will be discussing in subsequent topics.
- Creating a layout of data structures that results in efficient memory accesses
- Employing optimized HPC libraries where possible in your program
- Using appropriate compiler options when building your application
These principles are interrelated. For example, good memory layout and a favorable access pattern may produce reasonably fast code; but to make it as fast as possible, the compiler may also need to be given the right flags. In another case, the best data structures for your application may turn out to be the ones that are compatible with a certain HPC library, so you can take advantage of the excellent memory organization and specialized compiler flags that are already built into the software.
Although compiler flags and libraries can be simple to use, understanding why they work requires knowledge of the system, especially a working knowledge of the memory hierarchy. Our discussion therefore begins with microarchitectural concepts such as caches, vector units, and data locality. After all, libraries can change over time, as competing alternatives are rolled out. Similarly, compiler options can change sporadically, and they may be vendor-dependent. But the need to access memory is fundamental, so we'll want to take a look at how it is structured first.
If you truly have no interest in getting acquainted with the inner workings of a microprocessor, you can just skip ahead to the material on HPC libraries.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)