Application Example
A typical use of MPI_Scatter might arise when you distribute initial data in a data-parallel code. This is the situation that occurs normally when you've parallelized your code via domain decomposition. In the illustration below, process 0 has all the data initially. The colors show a possible target distribution of data points across four processes, including process 0.
But what if the number of points is not evenly divisible by the number of processes? Then not all the processes will receive the same number of data points, obviously. This says that we'll need to use MPI_Scatterv instead of MPI_Scatter — which is what we'll try doing later on, in the exercise.
The "v" variants
The MPI_Scatterv operation is just one from a family of variants that allow for greater flexibility when calling MPI collective scatter/gather routines.
- MPI_Scatterv, MPI_Gatherv, MPI_Allgatherv, MPI_Alltoallv
- What does the "v" stand for? varying – sizes, relative locations of messages
- Routines for discussion: MPI_Scatterv and MPI_Gatherv
Maybe you could say that this example is brought to you by the letter V! The MPI routines we want to focus on all end with V, like MPI_Scatterv. You can pretend that the V stands for something like "varying" or "variable". This is because these routines allow you to vary both the (1) size and the (2) memory locations of the messages that you are using for the communication. We are looking at MPI_Scatterv and MPI_Gatherv in this example, but you can easily extend the ideas to MPI_Allgatherv and MPI_Alltoallv.
Advantages
- More flexibility in writing code
- Less need to copy data into temporary buffers
- More compact final code
- Vendor's implementation may be optimal (if not, you might be trading performance for convenience)
As we'll see, there are several advantages to using these more general MPI calls. The main one is that there is less need to rearrange the data within a process's memory before doing an MPI collective operation. Furthermore, when you use these calls, you give the vendor an opportunity to optimize the data movement for your particular platform. But even if the vendor hasn't bothered to optimize an operation like MPI_Scatterv for you, it will always be more convenient and compact for you to issue just a single call to MPI_Scatterv if your data access pattern is irregular.
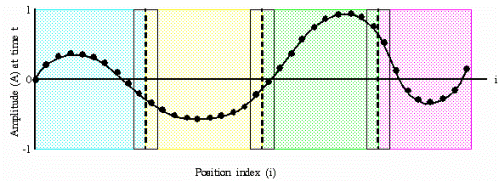
Note that in the diagram, there are some points (in the boxes) that are shared by more than one task. It would be interesting if scatterv could distribute such points to both processors involved. But according to the MPI standard, "The specification of counts, types, and displacements should not cause any location on the root to be read more than once." There is no obvious reason to create such a restriction; probably, it was done to preserve symmetry with the gatherv operation. For gatherv, one can see that doing multiple writes to the same location on root would lead to trouble; e.g., the result would not be deterministic. For scatterv… let's just say it is unwise to go against the standard, even if it happens to work.
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)