Parallel HDF5
Parallel HDF5 (PHDF5) is the parallel version of the HDF5 library. What is HDF5, and why should one use it? The Hierarchical Data Format version 5 (HDF5) is a file format and associated library that is typically used to manage data in HPC. HDF5 is built around a data model that can represent complex data objects using a portable, self-describing file format designed for efficient I/O. The HDF5 API provides tools to create, manipulate, and view large data collections. Though originally based on the single process model, it was extended to support parallel usage. It also provides techniques for optimizing I/O and storage performance.
PHDF5 utilizes MPI to parallelize operations like create, open, close, edit, read and query for HDF5 files. For example, when an HDF5 file is opened with an MPI communicator, all the processes within the communicator can perform various operations on the file.
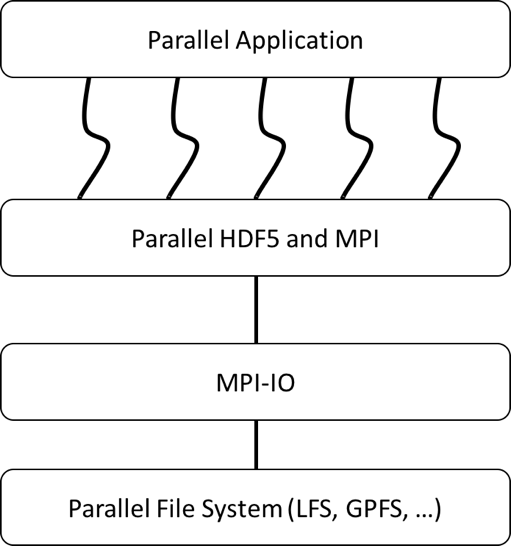
The following figure shows a typical parallel application and the supporting software stack that is needed to enable parallel I/O using parallel HDF5, or PHDF5. Underlying PHDF5 is MPI-IO, which must, in turn, be supported by a parallel file system such as LFS (Lustre) or GPFS.
In this topic, we focus on the parallel usage of HDF5.
Here are a few relevant facts about how PHDF5 works with HDF5 files:
- All processes within the communicator can perform I/O on a single HDF5 file in parallel
- There is a single file image for all the processes
- PHDF5 files are essentially no different from serial HDF5 files
- PHDF5 can therefore go beyond the "one file per process" kind of I/O parallelization
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)