Deep Learning underlying AI
Deep neural networks are powering many recent advances in AI, including computer vision systems, generative Natural Language Processing (NLP) applications, and innovative frameworks for scientific research. As noted, neural networks provide a flexible substrate for representing complex functions, as encoded through their network architecture. Network architecture encompasses both the general topology of neural networks (number of nodes, number of hidden layers, etc.) as well as the types of computations carried out by nodes and layers. While any sufficiently large neural network can work as a universal function approximator, a "plain" neural network without some internal structure might need to be very large to handle particular kinds of data, might be slow in converging during training, or might not generalize well to new data. Therefore, specialized classes of architectures have been developed to support particular problem domains, and the design and engineering of novel architectures or architectural motifs to be performant in different problem domains is a major area of research. Complex AI systems are built out of subnetworks with different structure, functionality, roles, and relationships. In addition, deep neural networks can be trained using a combination of methodologies and protocols, and combined with other AI techniques in order to address complex problem domains. We briefly describe some of these topics below.
Prior to the widespread use of deep learning neural networks, much of the activity in machine learning and related fields such as signal processing involved carrying out extensive research into what features in data were important for some analysis of interest. Those features might be spatiotemporal patterns in the case of signal detection and identification, geometric patterns in image processing and analysis, or statistical anomalies that might indicate something out of the ordinary. Much of the power and utility of deep learning neural networks is that they can free researchers from having to do that up-front work to identify features of potential importance; rather, neural networks can often learn those features through the process of being trained on data, and at the same time do a more effective and efficient job than humans themselves. A challenge, however, lies in finding the right neural network architecture for a specific application in order to support that feature learning. Hence, it has been said that deep learning represents a shift in emphasis from feature engineering to architecture engineering. Below, we describe a few examples of how different neural network architectures can support different classes of problems.
Image recognition, computer vision, and Convolutional Neural Networks
Image recognition and computer vision — the process of identifying entities in an image or video — is a central task in many AI applications. These capabilities are often achieved by training a neural network on a large number of images (inputs) and associated information (labels) about what kinds of objects those images contain. By being presented with many different examples of various types of objects (dogs, cats, flowers, baseballs, pizzas, etc.), the neural network can learn to identify one of those object categories when presented with a new unseen image. One thing that an image recognition system needs to be able to do is to recognize an object category regardless of where that object is located within an image. If one image has a flower in the upper-left corner, and another has a flower in the lower-right corner, one would hope that an image recognition system could efficiently encode something about flowers wherever they are, without separately having to encode information about flower-in-the-upper-left as opposed to flower-in-the-lower-right. In mathematical terminology, we say the recognition should be "translation invariant", so that the encoding of flower does not change as it is moved around (translated) in an image.
Image data are numerically rastered in a 2D array of numbers (typically with a single value per pixel for grayscale images, or three values per pixel for color images in a format such as RGB). Those arrays of numerical values are fed as inputs to a neural network, and specific nodes and edges in the neural network are connected to specific pixels in the image. In a garden variety neural network, such as the one schemetically depicted on the previous page, the key visual determinants of "flower" would have to be separately learned by different parts of the neural network, for those parts of the network that were linked to the location of a flower in the image.
Convolutional Neural Networks (CNNs) address this problem by introducing convolutional layers, and associated elements such as pooling layers, that are capable of identifying objects in larger images by implementing this property of translation invariance. Popular image classification models that have been trained on large collections of images, such as VGG-16 and ResNet50, make heavy use of convolutional layers to recognize different types of objects in images.
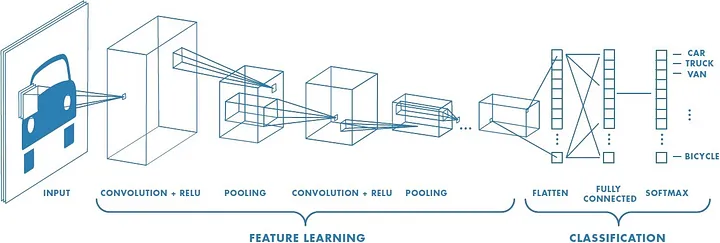
Image credit: Sumit Saha, https://medium.com/towards-data-science/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
Natural Language Processing, self-attention mechanisms, and transformers
When confronted with a body of text for use in Natural Language Processing (NLP), a neural network needs to be able to learn about complex relationships within text that might be distributed over long distances. For example, the meaning or part of speech of a particular word introduced at the beginning of a sentence might not become apparent until the end of a sentence, or a pronoun used in one sentence might refer to an entity named in some earlier sentence. These kinds of long-range associations are rather different than the local patterns in images that a CNN is good at detecting. In order to build neural networks capable of capturing relationships among words distributed throughout a body of text, researchers have developed a number of different network architectures. Earlier work explored the use of recurrent neural networks (often used to model time series or other extended sequences) and networks with long short term memory (LSTM). But the introduction of the Transformer architecture in 2018, along with their support for self-attention mechanisms that enable modeling of long-range context dramatically changed the landscape of NLP-based applications. The "GPT" family of models and applications (ChatGPT, GPT-3, GPT-4, etc.) is so-named to reflect its formulation as a "Generative Pre-trained Transformer". Similar, the widely used "BERT" model, which is used for different sorts of NLP tasks, derives its name from "Bidirectional Encoder Representations from Transformers".
We will not go into the technical details, other than to note that self-attention mechanisms enable a transformer network to associate, for each word in a passage of text, numerical values indicating how much "attention" it should pay to other words in the passage, in order to build up associations, context, and meaning. As a result, the time required to train of transformer network typically grows quadratically with the number of words or tokens that it is currently working with in a processing window, since for each of N words, the network needs to compute attention scores for N-1 other words. Trying to develop effective network architectures with computing times that do not scale so quickly with N is an active area of algorithmic research.
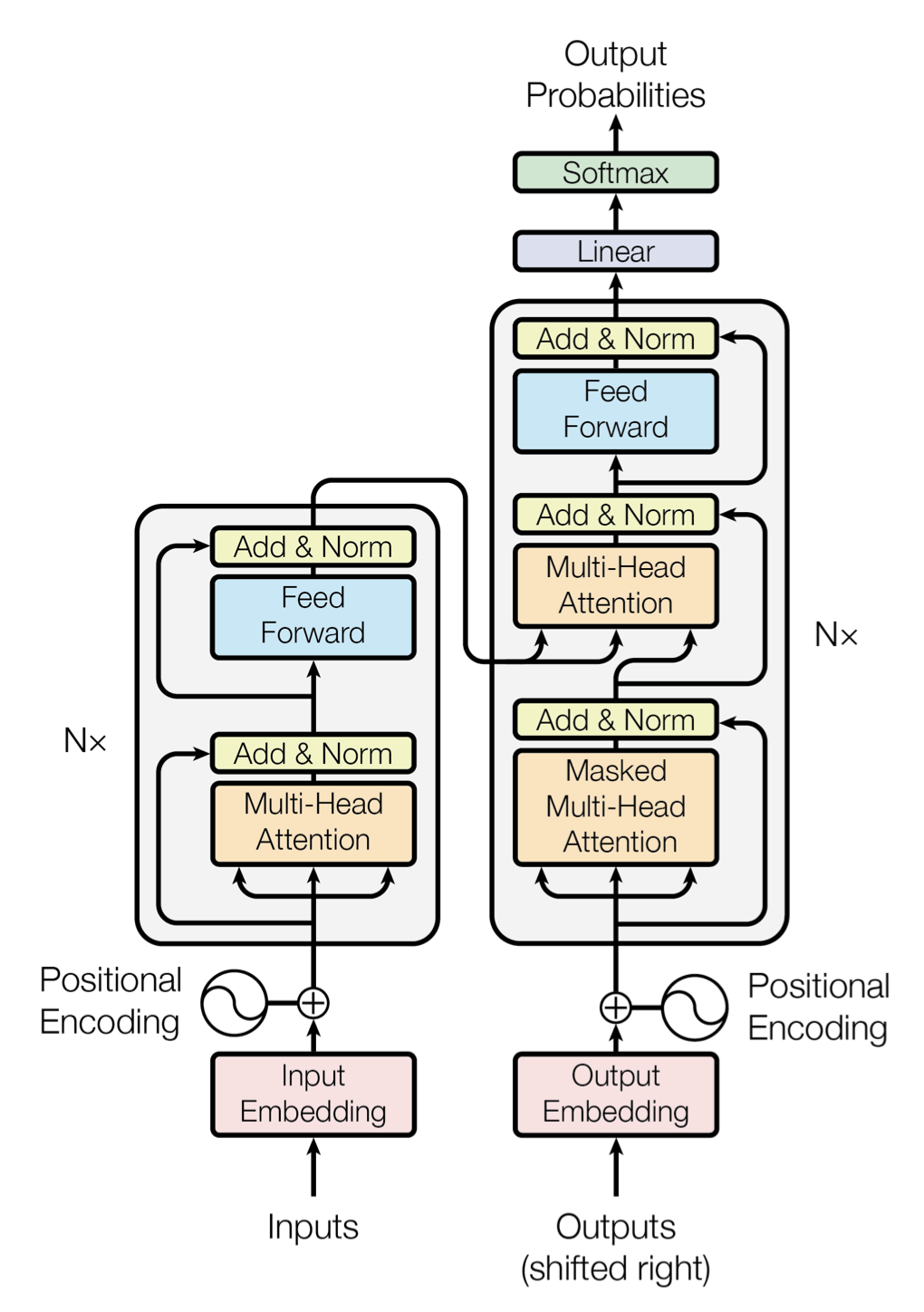
Image credit: Vaswani et al., "Attention Is All You Need", https://arxiv.org/abs/1706.03762
Encoders, decoders, and autoencoders
Encoder-Decoder architectures are widespread throughout AI applications. Encoders are neural networks that take inputs, which are typically in some high-dimensional data space, and project those data down to some lower-dimensional latent or embedding space. From the latent space, a second neural network — the Decoder — expands the data back out to some output space, which might also be high-dimensional. What's so useful about that?
One common use of Encoder-Decoder networks is in processes such as machine translation among different human languages. An encoder might transform words or sentences from a specific input language (such as English) down to some common latent space that can represent words and associations in any language. From there, a decoder can reconstruct the words in a specific output language (such as French), without the need to build separate networks that translate each separate input language into a target output language. For L different languages, one needs to only develop 2*L mappings (language to latent, latent to language), instead of L*(L-1) different mappings between all pairs of languages.
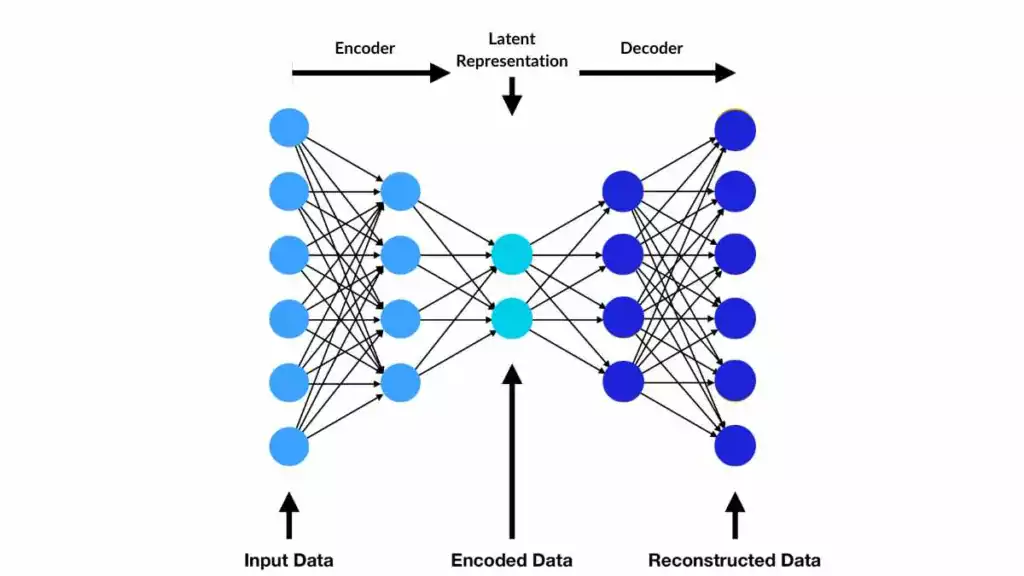
Image credit: Neri Van Otten, https://spotintelligence.com/2024/02/29/bert-nlp/
While language translation involves connecting two distinct input and output spaces (e.g., English and French), encoders and decoders are often paired together to form autoencoders, which connect the same input and output space. An autoencoder is often used to support dimensionality reduction, the process of reducing a high-dimensional data set to a lower-dimensional representation that might be useful for visualization or interpreting key patterns in data. In such an application, one trains the encoder and decoder networks to be able to reconstruct as well as possible the original input data in the decoded outputs, having gone through the compression into a smaller latent space. There is no unique or perfect way to capture all of the relationships among high-dimensional data points in some lower dimensions, but by requiring the reconstructed output data to be as close as possible to the original input data, one can be confident that the structure learned in the low-dimensional latent space is a useful summary or compression of the major features in the data.
A standard autoencoder just connects the data samples in the input space and the reconstructed samples in the output space, but a variational autoencoder (VAE) goes a step further to identify and encode probability distributions that summarize the data in the latent space. By developing a model of the distribution of data within the latent space, a VAE can be used for generative applications that navigate through the continuous space between the data.
Integration of ML, DL, and other AI techniques for complex problems
Many important and impressive AI applications combine many different techniques from Machine Learning, Deep Learning, and other types of computations. AlphaGo, for example, is a program developed by DeepMind that has learned to play the game Go, considered by many to be the most complex game invented by humans, at a level that can beat the best human Go players. AlphaGo was initially trained in a supervised fashion, by feeding in information about moves and game results from many historical games played between humans. Once it became able to play Go reasonably well, it was trained further through a process of reinforcement learning, whereby it generated new playing strategies and received quantitative feedback about what strategies worked well in different situations. Those ML/DL capabilities are integrated with other computational techniques such as Monte Carlo tree search, which enable the program to efficiently query the large space of possible moves to make. Thus, even though AlphaGo "learned" how to play Go, it had to be guided through that process with a great deal of insight and engineering on the part of its human developers.

Image credit: Google DeepMind, https://deepmind.google/research/breakthroughs/alphago
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)