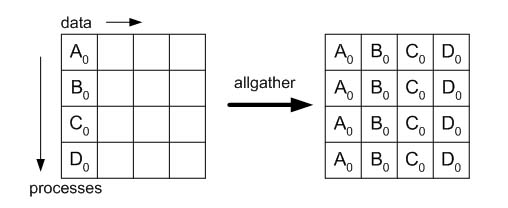
Allgather
MPI_Allgather can be thought of as an MPI_Gather where all processes, not just the
root, receive the result. The jth block of the receive buffer is reserved for data
sent from the jth rank; all the blocks are the same size. MPI_Allgatherv works
similarly, except the block size can depend on rank j, in direct analogy to MPI_Gatherv.
It's not surprising, then, that the syntax of MPI_Allgather and MPI_Allgatherv
turns out to be close to MPI_Gather and MPI_Gatherv, respectively. The main
difference is that the argument root is dropped from the argument lists
because there is no root process for the "all" type commands.
Allgather[v] syntax
MPI_ALLGATHER(sbuf, scount, stype, rbuf, rcount,
rtype, comm, ierr)
MPI_ALLGATHERV(sbuf, scounts, stype, rbuf, rcounts, displs,
rtype, comm, ierr)
Allgather[v] parameters:
sbuf- is the starting address of the send buffer
scount[s]- is the [array of the] number of elements to send to each process
stype- is the data type of send buffer elements
rbuf- is the address of the receive buffer
rcount[s]- is [an array containing] the number of elements to be received from each process
[displs]- is an array specifying the displacement of data relative to rbuf
rtype- is the data type of the receive buffer elements
comm- is the group communicator
Info: The arguments are the same as MPI_Gather or MPI_Gatherv, except there is no
root argument.
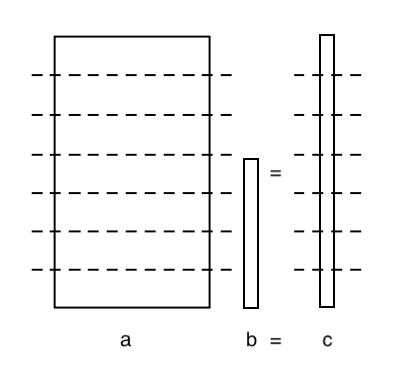
Example: matrix-vector multiplication using MPI_Allgather
- This example is similar to previous ones, but it uses 7 MPI processes.
- The matrix is distributed by rows, so the output vector will be too.
- The output vector is needed in its entirety by ALL processes.
MPI_Allgather Example Code
/* This allgather example assumes 7 total ranks */
float apart[25,100], b[100], cpart[25], ctotal[175];
int i, k;
⋮
for(i=0; i<25; i++)
{
cpart[i]=0;
for(k=0; k<100; k++)
{
cpart[i]=cpart[i]+apart[i,k]*b[k];
}
}
MPI_Allgather(cpart, 25, MPI_FLOAT, ctotal, 25, MPI_FLOAT,
MPI_COMM_WORLD);
! This allgather example assumes 7 total ranks
REAL apart(25,100), b(100), cpart(25), ctotal(175)
INTEGER I, K
⋮
! compiler will likely reorder these loops due to Fortran storage order
DO I=1,25
cpart(I) = 0.
DO K=1,100
cpart(I) = cpart(I) + apart(I,K) * b(K)
END DO
END DO
CALL MPI_ALLGATHER(cpart, 25, MPI_REAL, ctotal, 25, MPI_REAL, &
MPI_COMM_WORLD, ierr)
©
|
Cornell University
|
Center for Advanced Computing
|
Copyright Statement
|
Access Statement
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)