DeepONet Architecture
DeepONet (Deep Operator Network) is the practical implementation of the Operator Universal Approximation Theorem.
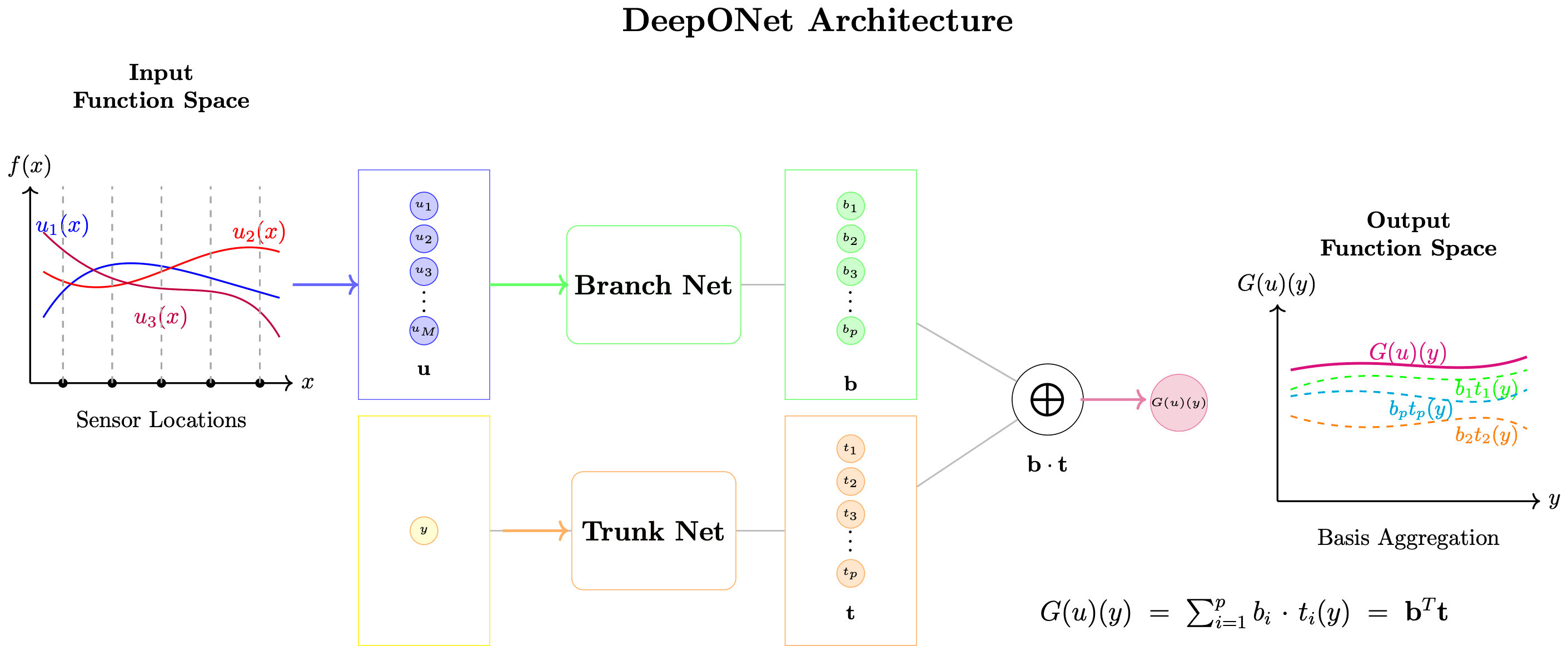
Core Architecture
\[ \mathcal{G}_\theta(u)(y) = \sum_{k=1}^p b_k(u) \cdot t_k(y) + b_0 \]
where:
- Branch network: \( b_k(u) = \mathcal{B}_k([u(x_1), u(x_2), \ldots, u(x_m)]) \)
- Trunk network: \( t_k(y) = \mathcal{T}_k(y) \)
- \( p \): Number of basis functions (typically 50-200)
- \( b_0 \): Bias term
Training Data Structure
Input-output pairs: \( (u^{(i)}, y^{(j)}, \mathcal{G}(u^{(i)})(y^{(j)})) \)
- \( N \) input functions: \( \{u^{(i)}\}_{i=1}^N \)
- Each function sampled at \( m \) sensors: \( \{u^{(i)}(x_j)\}_{j=1}^m \)
- Corresponding outputs at query points: \( \{\mathcal{G}(u^{(i)})(y_k)\} \)
Loss Function
\[ \mathcal{L}(\theta) = \frac{1}{N \cdot P} \sum_{i=1}^N \sum_{k=1}^P \left|\mathcal{G}_\theta(u^{(i)})(y_k) - \mathcal{G}(u^{(i)})(y_k)\right|^2 \]
Key Advantages
- Resolution independence: Train on one grid, evaluate on any grid
- Fast evaluation: Once trained, instant prediction (no iterative solving)
- Generalization: Works for new functions not seen during training
- Physical consistency: Learns the underlying operator
©
|
Cornell University
|
Center for Advanced Computing
|
Copyright Statement
|
Access Statement
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)