Layers
Convolutional Layer
The convolutional layer is the core building block of a CNN. It consumes two inputs: input feature maps and a set of filters, and generates output feature maps. The filter is applied to an area of the input feature map by doing a dot product. This dot product is then fed into the output feature map. Convolutional layers ensure the desired property of spatial invariance. No matter where the object is, the model can detect it correctly.
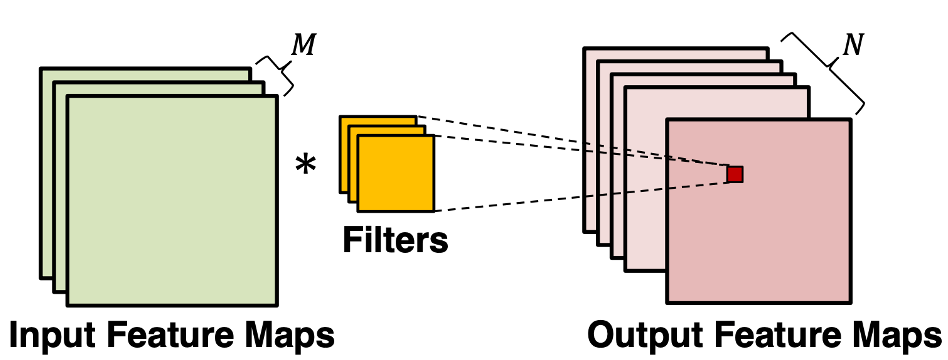
Image source: [1]

Image source: [2]
Pooling Layer
Convolution exploits the spatial information of pixels, but we still have problems when an object is moved, rotated, or shifted in the image. One common approach to cope with this issue is to downsample the information from the convolution results. Thus, only the large or important structural elements are preserved and then passed to the following layers. In a CNN, we can downsample by using a pooling layer. Common pooling operations include max, min, avg, etc.
Dropout Layer
Dropout layers reduce the problem of overfitting. Given a probability of dropout, it randomly drops some neurons from the fully-connected layer. Adding such randomness into the network can increase its generalization to different situations, as it has been proven to be an effective regularization algorithm. One thing to mention is that dropout only happens during the training stage. When we train the model, if a neuron is selected by the dropout layer, it will not contribute to the following layers, its gradient will not be computed, and its parameter will not be updated.
[1] Bernard. URL: https://classes.cornell.edu/browse/roster/FA22/class/ECE/5775
CVW material development is supported by NSF OAC awards 1854828, 2321040, 2323116 (UT Austin) and 2005506 (Indiana University)